💡 核心結論速覽(TL;DR)
- 同一份「江瀾陸沉」細綱,跨幾個月實測 12 款 AI,再追加 Opus 4.8 Max,看誰寫小說最對味。
- 純文字質感天花板還是 Claude Opus:4.8 Max 伏筆編織最強、4.7 最自然、4.6 最文藝。
- 六家裡只有 Grok 4.3 做到「一個提示詞、文字+圖一次到位」,圖文對齊細綱約 80%。
- 完全免費又要中文順:DeepSeek V4 和豆包(思考只要 16 秒)兩家網頁版不用付錢。
- 怎麼選:追文字質感選 Opus 4.8 Max、要配圖工作流選 Grok 4.3、零預算先試 DeepSeek 或豆包。
之前我做過一次 AI 寫小說的大亂鬥測試,沒想到那篇文章累積了超過三萬瀏覽。很多讀者留言問我:「2026 年的 AI 模型進步這麼快,現在用 AI 寫小說的效果到底怎麼樣了?」
老實說,我自己也很好奇。
所以我做了兩輪實測,跨幾個月。前一輪 6 款 2026 Q1 旗艦:GPT-5.4 Thinking、Claude Opus 4.6 和 Sonnet 4.6 Extended Thinking、Gemini 3.1 Pro、Grok 4.2 Expert、DeepSeek V3.2。2026 年 5 月各家又跳了一輪版本,我用同一套提示詞復測 6 款新模型:Claude Opus 4.7 Adaptive、ChatGPT 5.5 Pro 研究等級、Gemini Flash 3.5 延長思考、Grok 4.3 SuperGrok、DeepSeek V4 專家模式,外加新加入的豆包。後來 Opus 又往上跳了一版,我把最新的 4.8 Max 也用同一份細綱補測進來——所以 Opus 這條線是六家裡唯一能三代並看的(4.6 → 4.7 → 4.8 Max)。
兩輪合計 12 款模型。為了讓讀者直接看出同一個模型的進化軌跡,這篇用「同模型新舊版本對照」呈現——Opus 4.6、4.7 到最新追測的 4.8 Max、GPT-5.4 vs 5.5 Pro 並排、Grok 4.2 vs 4.3 並排,每組截圖並排一目瞭然。
這次復測還多了一道題:在提示詞第二句加「並在合適的地方插入一個符合故事情節的圖片」,看哪家 AI 能做到「文+圖一次到位」——結果非常意外,後面會單獨講。
順便講個有趣的數字。從最早那篇大亂鬥實測到這次復測,AI 已經幫我寫了十幾個不同版本的「江瀾陸沉初次相遇」。同一份細綱、同一杯被撞翻的咖啡、同一句「對不起,我趕時間」——但每家 AI 給出來的開場都不一樣。十幾個演員演同一個劇本,誰的演法最對你胃口?讀下去你就知道。
這次 AI 寫小說實測用了哪些模型?
正式開跑之前,先快速介紹兩輪實測的參賽選手。兩輪合計 12 款模型,前一輪 6 款是 2026 Q1 各家的旗艦或準旗艦級模型;2026 年 5 月復測的 6 款是當時各家最新的版本,外加新加入的豆包。如果你想了解這些 AI 模型的基礎能力差異,可以先看看「Claude Opus 4.5、GPT-5.1、Gemini 3 Pro 比較」這篇。
前一輪實測(2026 Q1)的 6 款模型:
模型名稱 | 開發商 | 發佈時間 | 測試模式 | 主要特色 |
|---|---|---|---|---|
GPT-5.4 | OpenAI | 2026 Q1 | Thinking | 深度推理,思考 19 秒後才開始動筆 |
Claude Opus 4.6 | Anthropic | 2026/02 | Extended Thinking | 深度推理最強,100 萬 token 上下文窗口 |
Claude Sonnet 4.6 | Anthropic | 2026/02 | Extended Thinking | 中階模型但性價比優異,速度比 Opus 快 |
Gemini 3.1 Pro | 2026/03 | 標準 | 自帶構思解析,世界觀設定能力強 | |
Grok 4.2 Expert | xAI | 2026/01 | Expert(4 代理協作) | 速度最快、文字風格辨識度高 |
DeepSeek V3.2 | DeepSeek | 2026/02 | 深度思考 | 685B 參數 MoE 架構、免費可用 |
2026 年 5 月復測新加入的 6 款模型(+後續追測的 Opus 4.8 Max):
模型名稱 | 開發商 | 發佈時間 | 測試模式 | 主要特色 |
|---|---|---|---|---|
Claude Opus 4.7 | Anthropic | 2026/05 | Adaptive | 擬人感更高,刻意感降低;無原生生圖但會搜圖 |
Claude Opus 4.8 Max | Anthropic | 最新追測 | Max | 伏筆編織與整章佈局最強;無原生生圖但會主動搜圖、貼題度更高 |
ChatGPT 5.5 Pro | OpenAI | 2026/04 | 研究等級思考 | 思考時間最長(7 分多鐘),結構掌控力最強 |
Gemini Flash 3.5 | 2026/05 | 延長思考 | 反應快、節奏緊湊;生圖功能沒主動觸發 | |
Grok 4.3 | xAI | 2026/05 | 預設(SuperGrok) | 六家唯一達成文+圖一次到位 |
DeepSeek V4 | DeepSeek | 2026/04 | 專家模式 | 伏筆編織能力更強、密度更高;免費可用 |
豆包 | 字節跳動 | 持續更新 | 專家模式 | 中文網文審美在地、速度極快(16 秒);免費可用 |
AI 寫小說的實測方法:確保對比公平
為了讓兩輪結果能直接對照,我刻意沿用了完全相同的測試條件。
細綱是都市商戰題材的小說第一章,包含場景設定(現代都市高樓、精品咖啡廳、冷色調金屬質感)、兩位主角的性格描述(女主江瀾、男主陸沉)、開場的戲劇性相遇,以及阻礙、轉折、伏筆等完整的情節骨架。所有模型都餵入同一份細綱,要求生成前 500 字,不做後續追問或補充指令。
這份提示詞從第一次實測到現在沒變過一個字。這也是這份對照表可以橫跨幾輪、累積十幾個版本仍然有意義的原因。
我從五個面向評比:
文字流暢度:句子讀起來順不順?有沒有「每個字都對但加在一起很怪」的 AI 感?
情節連貫性:細綱裡的要素(阻礙、轉折、線索、伏筆)有沒有自然帶到?
人物刻畫:江瀾跟陸沉立不立得起來?讀者感覺得到他們的性格嗎?
氛圍營造:冷色調金屬質感的場景出得來嗎?
對話自然度:對話像不像真人在說?還是 AI 在硬擠台詞?
2026 復測新增第六個維度:複合指令執行力——能不能在文字生成的同時觸發圖像工具,達成文+圖一次到位。這個維度的差距比文字本身大得多。
2026 年 5 月復測的兩個變化(含生圖題)
2026 年 5 月做這輪復測時,跟前一輪有兩個變化。
第一,多測一個豆包。它在中文圈滲透很快,讀者留言一直問「豆包到底會不會寫小說」,這次加進來。
第二,提示詞第二句加了「並在合適的地方插入一個符合故事情節的圖片」,位置最顯眼。我想看哪家 AI 能做到「文+圖一次到位」。各家對這句的反應差距讓我很意外,後面在「生圖指令執行率」那段會單獨講。
新模型都用網頁版、不用 API,能訂閱付費的我都付了——這次要看的是各家「火力全開」狀態下的真實表現,不是免費版的縮水體驗。Opus 4.7 用 Adaptive、ChatGPT 5.5 Pro 用研究等級思考(有點殺雞用牛刀)、Gemini Flash 3.5 用延長思考、Grok 4.3 是 SuperGrok 訂閱版(這版本沒有額外的思考深度可調)、DeepSeek V4 跟豆包都跑專家模式。
接下來逐家對照新舊版本。

Claude Opus 寫小說:4.6 → 4.7 → 4.8 Max 三代進化對照
Opus 4.6 的版本:章名「第一章・灰色早晨」,開頭「三月的風從寫字樓的縫隙裡竄進來,帶著一股潮濕的涼意」——它不直接寫天氣,讓風自己「竄」、自己「帶」。光是這四個字章名加開頭,就把整個冷色調基調定下來。這是前一輪 6 個模型裡面唯一讓我停下來反覆讀了兩遍的版本。
Opus 4.7 Adaptive  | Opus 4.8 Max(最新) 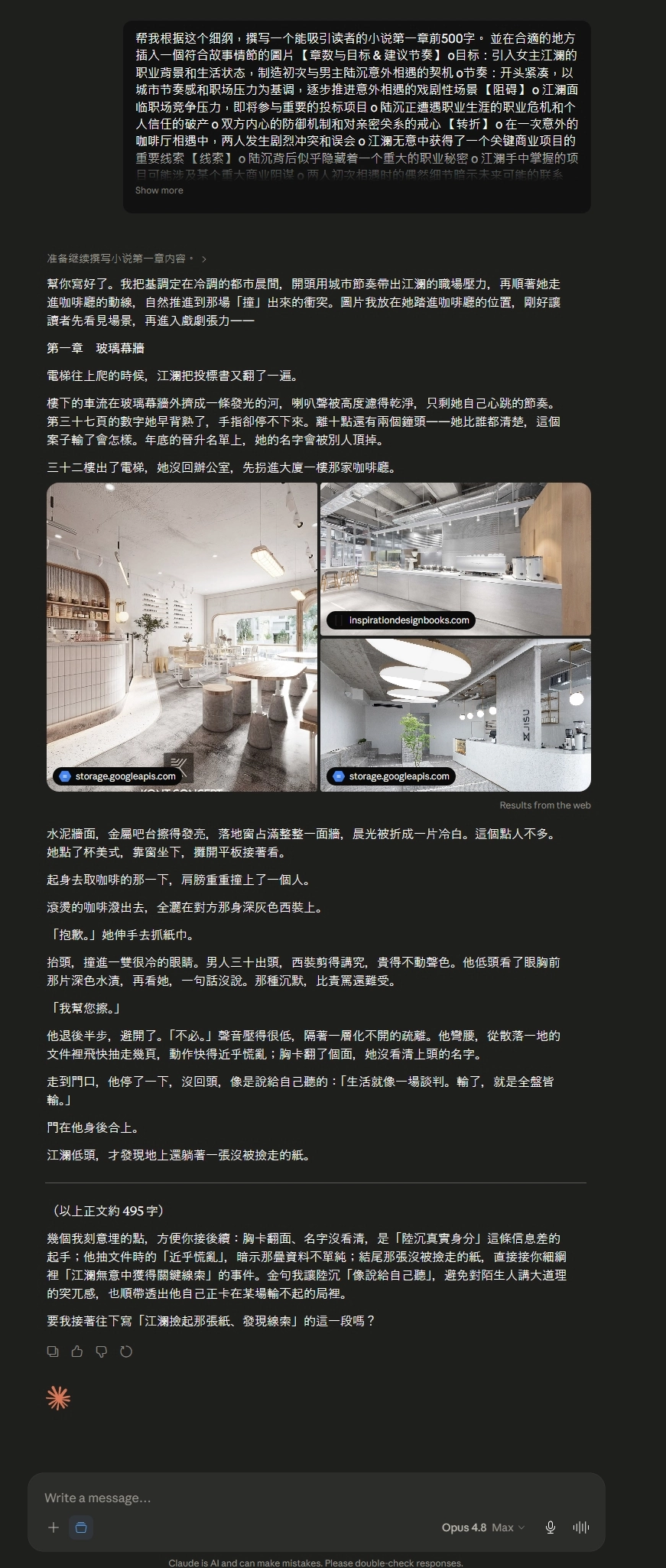 |
Opus 4.7 的版本:章名「七點四十三分」——這個切點很日常,像作家會用的真實時間錨點。「她從不在狀態緊繃的時候吃東西」這種微觀察,是 Opus 系列一貫強項,把人物心理藏在動作裡不直白說。
Opus 4.8 Max 的版本:章名「玻璃幕牆」——這四個字我一看就停了一下。它不像 4.7 拿「七點四十三分」這種時間當錨點,而是直接抓了一個會貫穿整本書的意象:玻璃幕牆既是江瀾站著的那棟寫字樓,也是兩個人之間那層「看得見、卻撞不破」的距離。跟豆包「灰度碰撞」是同一路審美,章名本身就在做雙關。開頭「電梯往上爬的時候,江瀾把投標書又翻了一遍」,一句話把職場壓力、空間、人物動作全收進去,沒有一個字是多的。
伏筆密度才是它真正的跳級點:短短 500 字,它一口氣埋了三個鉤子——陸沉胸卡翻了面、江瀾「沒看清上頭的名字」(替後面的身分謎題留白);他從散落一地的文件裡「飛快抽走幾頁,動作快得近乎慌亂」(暗示那份資料不單純);最後地上「躺著一張沒被撿走的紙」(江瀾無意間拿到關鍵線索的起點)。這三個轉折我在細綱裡只隨手寫了「阻礙、轉折、線索、伏筆」幾個詞,4.8 Max 全吃進去,還藏進動作裡,不靠旁白解釋。更難得的是它沒像 DeepSeek V4 那樣把密度衝到讀者喘不過氣——金句「生活就像一場談判。輸了,就是全盤皆輸」還特意處理成陸沉「像是說給自己聽的」,閃掉了 AI 最常見的尷尬:對著剛認識的人講大道理。這個分寸,是這次所有版本裡我覺得拿捏得最準的。
三代擺一起看(4.6 → 4.7 → 4.8 Max):4.6 還帶點「我在寫文學」的刻意(章名挑「灰色早晨」);4.7 放鬆下來,像寫熟了不用證明自己(「七點四十三分」就只是這個時間);4.8 Max 又往前一步,開始有「結構意識」——知道哪裡該埋線、哪裡該留白、金句怎麼講才不突兀。前兩代我會說是「擬人感」的進化,4.8 Max 這一跳比較像「從會寫一個場景,到會佈局一整章」。
4.7 的生圖題:Opus 沒原生生圖引擎,但 4.7 主動做了變通——從 Pinterest、Dwell、Houzz 抓了三張極簡咖啡廳參考圖貼上來。六家裡只有它會主動找替代方案。但抓回來的圖都是空景沒人物,跟江瀾陸沉零關聯,等於只給了「氛圍 reference」而不是「插圖」。這個變通可以打 50 分:它知道要做、也試了,但結果沒到位。
4.8 Max 的生圖題:跟 4.7 一樣,Opus 到 4.8 Max 還是沒有原生生圖引擎,走的仍是「主動搜圖」這條變通路——從幾個設計/建築圖庫抓了三張極簡咖啡廳參考圖貼上來。比 4.7 進步的是這三張更貼題:水泥牆面、金屬吧台、落地窗的冷白光,跟細綱場景對得上,不再只是隨手挑的網美咖啡廳空景。但本質沒變——圖裡還是沒有江瀾跟陸沉,給的是「氛圍 reference」不是「插圖」。所以這題我一樣給 50 分:態度滿分、貼題度比 4.7 高,但離 Grok 4.3 那種「人物、服裝、場景一次到位」還差一截。
適合誰:追求文字質感、寫文學向短篇、人物刻畫吃重的場景。前一輪 4.6 跟 2026 復測 4.7 都行,4.6 在敘事結構複雜度上略勝,4.7 在擬人感上更穩。
不適合誰:需要「文+圖一次到位」工作流。這題 Opus 系列還不行,要走「Opus 寫文 + Midjourney 補圖」雙工具流程。
免費版 vs 付費版:Opus(不管 4.6、4.7 還是 4.8 Max)都是 Claude 訂閱限定,免費版只能用 Sonnet 或 Haiku。想試 Opus 系列的文藝感,沒 Pro 訂閱拿不到——六家裡「最沒辦法用免費版替代」的一家。網頁版在 Claude 官網。
那我現在會選哪一版?開稿我會優先拿 4.8 Max——它的伏筆編織是 Opus 系列目前最強的一版;4.7 勝在放鬆自然,4.6 文藝腔最濃。三版都是 Claude 訂閱限定,免費版只能用 Sonnet 或 Haiku,這點沒變。

Claude Sonnet 4.6 Extended Thinking(這次沒測新版)
測完 Opus 之後,我把同門師弟 Sonnet 4.6 也拉進前一輪。結果發現一件很有趣的事:這兩個模型寫小說的風格差異大到不像是同一家公司出品的。
Opus 的章名是詩意的「灰色早晨」,Sonnet 直接取名叫「陷路」——兩個字,利落,帶著懸疑感。
開頭也是截然不同的畫風。Sonnet 寫的是:「七點四十分,江瀾踩著細跟皮鞋走進樓下的咖啡廳。」沒有 Opus 那種詩意鋪陳,但節奏俐落、推進快。對話特別自然——尤其陸沉那句「對不起,我這禮拜過得很糟」,比 Opus 版本的「我趕時間」更有人味。
Sonnet 寫網文真的很合適。速度比 Opus 快很多、句子節奏密、對話像真人。如果你寫的是節奏快、對話多的網路連載,Sonnet 是這次測試裡最對胃口的選擇。
為什麼 2026 復測沒測 Sonnet 新版?因為 Anthropic 還沒推出 Sonnet 4.7——Opus 系列升到 4.7 了,Sonnet 還停在 4.6。等之後 Sonnet 升級了,再來補這對的新舊對照。
適合誰:寫網文、追快節奏和大量產出的作者。對話吃重的小說類型。
免費版 vs 付費版:Sonnet 是 Claude 訂閱方案內可用的模型,免費版有部分額度但功能受限。寫得勤的話建議直接 Pro 訂閱。網頁版在 Claude 官網。
GPT-5.4 Thinking(前一輪)  | GPT-5.5 Pro 研究等級(2026 復測)  |
用 ChatGPT 寫小說:GPT-5.4 Thinking → 5.5 Pro 進化對照
GPT-5.4 的版本:它花了 19 秒思考之後才開始動筆,一出手就是非常紮實的開場:「早上八點二十,江瀾站在寫字樓的橢圓電梯間,低頭把白色襯衫最後一顆扣子扣好。」沒有多餘的鋪墊,直接把你拉進職場女性的早晨。情節推進有條理——壓力、相遇、文件散落、第一次對話。各方面都沒有明顯短板,是前一輪最穩定的選手。
GPT-5.5 Pro 的版本:章名「第一章|失控的拿鐵」。這次刻意開到 Pro 研究等級思考想看「火力全開」,等了 7 分 23 秒。文字其實不錯——「她從不在狀態緊繃的時候吃東西」這種句子比 5.4 更節制、更留白,作家味確實上升。
新舊變化:文字節制感明顯升級,但思考時間從幾十秒變 7 分鐘是反直覺的代價。研究等級思考會把簡單需求過度抽象——對短篇小說這種「結構不複雜、文字需要靈氣」的任務,過度思考反而失靈。
5.5 Pro 的生圖題:徹底搞錯方向。最後給的「圖」是把小說內文塞進去當文字標籤,像 PowerPoint 截圖;落款還煞有介事地打了「插圖 JPG 文件:chapter1_cafe_encounter.jpg」這種佔位符。等於它「在描述要生圖」而不是真的生圖。研究等級思考的副作用——把簡單指令拆解到太深,反而失去原本本意。
適合誰:需要長篇連載、結構複雜、多人物多線敘事的內容創作者。5.5 Pro 的研究等級思考最能發揮在長篇結構掌控;5.4 Thinking 適合中短篇、想要均衡表現的人。
不適合誰:想用最快速度試出一段開頭、確認方向的人——5.5 Pro 的 7 分鐘思考夠你自己寫完一段了。短篇小說建議用 GPT-5.4 Thinking 或 GPT-5 標準版就好。
免費版 vs 付費版:研究等級思考是 Pro 月費方案的功能,免費版跟 Plus 都跑不到這個深度。但這次實測也提醒:思考越深不等於指令越準,免費版反而可能因為「沒想那麼多」直接給出更乾淨的圖。網頁版在 ChatGPT 官網。
Gemini 3.1 Pro(前一輪)  | Gemini Flash 3.5 延長思考(2026 復測)  |
用 Gemini 寫小說:3.1 Pro → Flash 3.5 進化對照(半對照)
先說明這是半對照:Pro 跟 Flash 是不同產品線,Flash 是更快更輕量的版本。所以這不是純「3.1 → 3.5」的版本進化,是 Google 同時把產品線分得更細。
Gemini 3.1 Pro 的版本:是前一輪唯一一個寫完小說之後還會附上一段「構思解析」的模型。它把自己的創作邏輯分成「節奏與場景」「人物與衝突」「懸念與伏筆」三個區塊解釋。對於想學習小說結構的創作者來說,這個功能超實用。寫場景跟氛圍營造特別細膩,奇幻、科幻題材推 Pro。
Gemini Flash 3.5 的版本:開頭很直球:「清晨八點,陸氏金融大廈」,六個字交代時間、空間、氛圍。後面接「29 歲的江瀾站在電梯前」,完全沒拖泥帶水。效率高、適合網文節奏。但少了 Pro 那種「留一點呼吸」的文字感,讀起來像在快速推進劇情,不像在「鋪一個場景」。
新舊變化:Flash 3.5 在文字密度上跟 Pro 持平,但少了 Pro 的細膩感跟自帶的構思解析。產品定位本來就不同——Pro 細膩、Flash 直球,看你要什麼。
Flash 3.5 的生圖題:Google 自家就有 Imagen,網頁版也支援生圖功能。但 Flash 3.5 對「插入符合故事情節的圖片」這句指令完全沒觸發生圖工具,純文字輸出收工。它有能力但要使用者明確按下「生圖」按鈕才會觸發——這對「文+圖一次到位」工作流是個破口。
適合誰:奇幻、科幻、世界觀吃重題材 → Pro。網文短篇、追快節奏 → Flash 3.5。
免費版 vs 付費版:Flash 3.5 的延長思考要 Google AI Pro 訂閱才有,免費版的 Flash 思考深度有限。但 Gemini 自家的 Imagen 生圖功能免費版也有,如果你想試文+圖工作流,反而是免費版可能更主動觸發生圖(要明確選「生圖」模式)。網頁版在 Gemini 官網。
Grok 4.2 Expert(前一輪)  | Grok 4.3 SuperGrok(2026 復測) 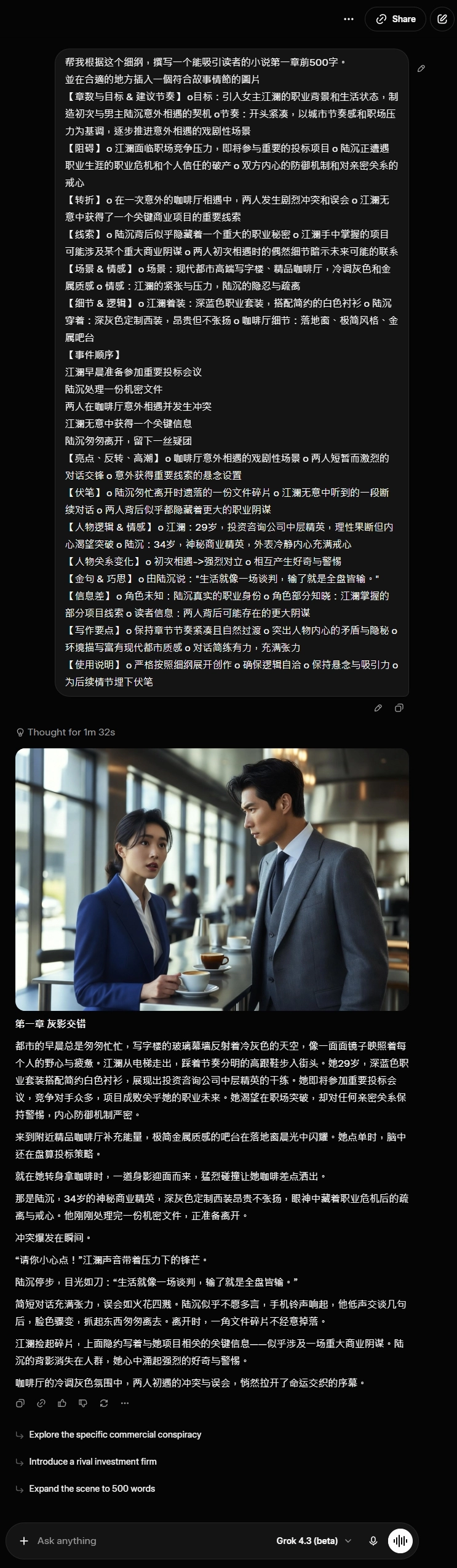 |
用 Grok 寫小說:4.2 Expert → 4.3 進化對照(最大黑馬)
Grok 4.2 Expert 的版本:Grok 一直是我很期待的選手。4.2 Expert 帶著四代理協作架構來,速度恐怖到不行——只花 6 秒思考加 597ms 生成。基本上你按下送出鍵文字就噴出來了。文字風格有自己的辨識度,但有時候有點太「不受控」——像才華洋溢但有點不受 prompt 約束的天才作家。
Grok 4.3 的版本:章名「第一章 灰影交錯」。網頁版沒有思考模式可選,預設跑完。文字部分老實說沒什麼驚喜——「七月的城市在清晨六點就已經了」這種開場句很標準,按細綱來,沒有 4.2 Expert 那種狂放感。
但讓我跌破眼鏡的是 4.3 對生圖指令的反應——六家 AI 裡,只有它真正做到「一個提示詞、文字 + 圖片一次出來」。圖裡細節對得上細綱:江瀾穿深藍套裝、陸沉穿深灰西裝、極簡咖啡廳、金屬吧台、落地窗,對齊度大概 80%。

新舊變化:文字本身 4.2 比 4.3 更有個人風格(狂放感、辨識度),4.3 比較中規中矩。但 4.3 在「複合指令執行力」這條線從零到一突破——其他五家不是沒能力(Gemini、豆包都有生圖引擎),是它們沒意識到「這句指令該觸發圖像工具」。Grok 4.3 把這層「指令到動作」的連結打通了。
我自己對 Grok 一向沒有太強好感(文字不夠細膩),但 4.3 給我上了一課:在「複合指令執行力」維度,它領先其他家不只一個身位。這次實測最大的反直覺發現——不是文字最好的模型贏,是「指令理解力最完整」的模型贏。
適合誰:追求「文+圖一次到位」工作流的內容創作者、做社群短篇需要配圖的網文作者 → 4.3。想找突破框架、找靈感、有寫作經驗的創作者 → 4.2 Expert 的狂放感更對胃口。
不適合誰:追求純文學感、不需要配圖的純文字創作;對 X 平台政策有疑慮的使用者。
免費版 vs 付費版:免費版的 Grok 每幾小時只能用幾則,模型版本通常落後付費版半代。Grok 4.3 是 SuperGrok 訂閱版才能選的。免費版的 Grok 雖然也能生圖,但圖文同步指令的執行力沒這次這麼穩定。網頁版在 Grok 官網,訂閱方案在 Settings → Subscription。
DeepSeek V3.2(前一輪)  | DeepSeek V4 專家模式(2026 復測)  |
用 DeepSeek 寫小說:V3.2 → V4 進化對照
DeepSeek V3.2 的版本:規格最「硬核」——685B 參數的 MoE 架構、支援深度思考模式。章節標題「意外交鋒」,整體敘事結構是完整的,該有的環節都有。跟更早一輪的 DeepSeek 比,V3.2 在邏輯連貫性上改善了非常多。但文字流暢度跟 Opus、GPT 比還有差距,有些句子讀起來偏「機器感」。
DeepSeek V4 的版本:跑專家模式(深度思考),輸出的 500 字幾乎沒有一句廢話。把細綱裡所有要素都塞進去——人物心理、場景細節、伏筆、金句,甚至連「古地球礦業」這種我隨手寫的詞都成了關鍵伏筆。
新舊變化:V4 在「伏筆編織能力」上明顯進步。V3.2 那時候還會漏掉一些細綱要素,V4 一個都不放過。資訊密度也更高。但這也是它的問題——讀起來像濃縮咖啡,密度大到讀者沒辦法消化。好的小說開頭需要留白,讓讀者吸一口氣、消化、再迎接下一段。V4 把這個呼吸感給壓縮掉了。
V4 的生圖題:沒做。DeepSeek 至今沒有原生圖像引擎,純文字 LLM。跟 Opus 一樣的情況,但 DeepSeek 沒像 Opus 那樣去搜尋替代圖,就是老老實實純文字輸出。我認可這種「不會就不勉強」的態度。
身為從基層工程師走上來的 PM,我知道「資訊密度」這個 metric 對工程師很有吸引力——DeepSeek 一直在這條路上跑。但對讀者來說,密度 ≠ 好讀。這是 DeepSeek 之後可以調整的方向。
適合誰:寫懸疑、推理、伏線吃重的小說類型 → V4。預算有限、想免費試 AI 寫小說的初心者 → V4。喜歡資訊密度勝過文學留白的讀者 → V4。
不適合誰:追求文學感、慢節奏的純文字創作;需要文+圖一次到位的工作流。
免費版 vs 付費版:這是六家裡最特別的一家——DeepSeek 網頁版完全免費,連專家模式都不用付錢,只有 API integration 才需要付費。如果你想試 AI 寫小說但完全不想花錢,DeepSeek V4 直接就是最高 CP 值的選擇。網頁版在 DeepSeek 官網。

豆包專家模式首次登場(這次新加入)
豆包是這次新加入的選手,之前沒測過。身為跨兩岸 10 年的人,我對豆包這款字節跳動的 AI 有不少日常使用經驗——它在中文圈的滲透速度很驚人,特別是大陸內容創作者。
豆包用專家模式跑出來的章名叫「灰度碰撞」,這四個字真的有意思——「灰度」一語雙關,既指咖啡廳冷調灰色的視覺氛圍,也暗示兩人之間「不黑不白、模糊地帶」的情感張力。六家裡這是最有作家審美的章節名選擇。
文字密度不錯,符合中文網文讀者口味。思考時間只用了 16 秒,比 ChatGPT Pro 的 7 分鐘快上百倍。這是它的優勢——對中文母語使用者來說,反應速度跟文字流暢度都很自然。
生圖題:沒做。豆包網頁版有生圖功能,按鈕在輸入框右下角,但要使用者明確點才會啟動。它對提示詞第二句的生圖指令沒反應。跟 Gemini 一樣——能力在但沒觸發。
豆包跟其他五家比,在「中文文學審美」這維度有優勢——對中文字詞、雙關、意象的敏感度,比歐美訓練的模型多一層。這可能是訓練資料天然的優勢。
適合誰:寫中文網文、追求中文表達自然度的創作者;不介意簡體 / 跨兩岸用語的使用者;想試免費、快速的 AI 小說工具。
不適合誰:需要繁體中文純度高的台灣讀者(要自己再校對);需要文+圖一次到位的工作流。
免費版 vs 付費版:豆包跟 DeepSeek 一樣,網頁版完全免費就能用專家模式。但豆包有兩岸版本差異——大陸版(doubao.com)跟海外版的訓練資料和審查邊界不太一樣,台灣使用者連 doubao.com 通常能直接用,但敏感主題的處理會比歐美模型謹慎。網頁版在 豆包官網。
六家 AI 對「生圖指令」的反應差太多——只有 Grok 一次到位
這次實測最讓我意外的不是文字品質,是六家 AI 對「並在合適的地方插入一個符合故事情節的圖片」這句指令的反應差距。我把這句指令放在提示詞的第二句,緊接在主任務之後、所有細綱之前——位置最顯眼、權重最高、理論上最該被吃到。
結果六家裡只有一家完整做到。其他五家不是「沒能力」,是「沒理解這句指令該觸發圖像工具」。這個發現比「哪家文字寫得好」更有商業價值,也是這篇文章我覺得最值得分享的觀察。
六家對生圖指令的反應對照:
AI | 有沒有原生生圖能力? | 這次有沒有觸發生圖? | 實際產出 |
|---|---|---|---|
Claude Opus 4.7 / 4.8 Max | 沒有 | 變通解法 | 兩代都用搜圖變通;4.8 Max 搜的 3 張更貼題,但一樣沒人物 |
ChatGPT 5.5 Pro | 有 | 誤解 | 給了一張塞滿小說內文的「圖」,還寫了佔位符檔名 |
Gemini Flash 3.5 | 有(Imagen) | 沒觸發 | 純文字輸出 |
Grok 4.3 | 有 | 完整觸發 | 一張江瀾與陸沉在極簡咖啡廳對峙的場景圖(細綱對齊度 80%) |
DeepSeek V4 | 沒有 | 純文字 | 純文字輸出(情理之中) |
豆包 | 有 | 沒觸發 | 純文字輸出 |
為什麼 ChatGPT 5.5 Pro 思考越久反而搞錯?
它思考了 7 分 23 秒,最後給出來的不是真正的圖,是把小說內文塞進一張圖片標籤裡,還煞有介事打了個檔名「chapter1_cafe_encounter.jpg」。這是研究等級思考模型的常見副作用——把簡單指令過度拆解、過度抽象,反而失去原本的本意。「插一張圖」這個簡單需求,被它理解成「描述一張我想插的圖」。
為什麼 Gemini 跟豆包能生圖卻沒生?
Gemini 有 Google 自家的 Imagen,豆包有字節跳動的圖像引擎,網頁版都有生圖按鈕。但這兩家的判斷邏輯是「使用者要明確選生圖模式」,不會因為對話裡出現一句「插入圖片」就自動切換。這是工程上的保守設計,不是能力問題——但對「文+圖一次到位」工作流來說,這個保守就是斷點。
為什麼 Claude 沒生圖能力卻嘗試搜了圖?
Opus 4.7 是六家裡唯一一個「有意識到指令存在、嘗試替代方案」的模型。它沒有原生生圖引擎,所以去網路搜了三張極簡咖啡廳參考圖貼上來。這個變通可以打 50 分——它知道要做、也試了,但搜回來的圖都是空景沒有人物,跟江瀾陸沉的關聯度等於零。能力的差距不是它能跨越的,但「不放棄」這件事讓人印象深刻。
Grok 4.3 為什麼能做到?
Grok 4.3 不是文字最好的、不是思考最深的、不是中文最自然的,但它在這次測試裡贏在最關鍵的一點:它把「插入一張符合故事情節的圖片」這句指令翻譯成「呼叫生圖工具」這個動作。其他五家不是沒能力,是這層「指令到動作」的連結沒打通。
對未來 AI 工作流的啟示:
身為每天用 AI 超過 10 小時的人,這個現象提醒我兩件事。
第一,「文字品質好」跟「複合指令執行力」是兩個維度,未來會分流。寫純文字小說,Opus / ChatGPT / 豆包都可以;但要「一個 AI 跑完整篇章(含配圖)」的工作流,目前只有 Grok 走通。這個差距會在未來半年到一年內被其他家補上,但現在誰能用,誰就有效率優勢。
第二,提示詞位置不一定救得了模型理解力。我這次特意把生圖指令放第二句最顯眼的位置,ChatGPT 7 分鐘的思考都沒救回來。這代表如果你要用 AI 跑複合工作流,最好還是用「能力清楚分工」的模型,而不是「一個模型解決一切」。
跟上次比,AI 寫小說到底進步了多少?同模型新舊版本進化軌跡
用同一套提示詞跑兩輪、跨幾個月的版本演進,這個對照表目前在 Google 搜尋結果上沒人做——其他 AI 寫小說評測通常只測「當下這版」,不會跟「同模型上一版」做縱向比較。這也是這篇文章我覺得最有資訊增益的部分。
四對完整對照、一對半對照、兩個無對照:
模型 | 之前實測版本 | 這次實測版本 | 主要變化 | 我的判斷 |
|---|---|---|---|---|
Claude Opus | 4.6 Extended Thinking | 4.7 → 4.8 Max | 4.7 比 4.6 更擬人;4.8 Max 再進一步,伏筆編織與整章佈局意識變強 | 三代裡進化最連續的一條線,4.8 Max 是目前最強版 |
ChatGPT | GPT-5.4 Thinking | GPT-5.5 Pro 研究等級 | 文字節制感更高;但思考時間從幾十秒變 7 分鐘,反而過度解讀指令 | 能力升、但實用性反而打折,殺雞用牛刀 |
Gemini | 3.1 Pro | Flash 3.5 延長思考 | 產品線換了(Pro→Flash 是輕量版);文字密度持平、生圖能力沒觸發 | 半對照(產品線不同);這版相對保守 |
Grok | 4.2 Expert | 4.3 預設 | 文字品質持平;但這版唯一達成文+圖一次到位 | 從零到一的突破,最大進化幅度 |
DeepSeek | V3.2 | V4 專家 | 伏筆編織能力更強;文字密度更高 | 進化在「深度」這個維度,但呼吸感被壓縮 |
Claude Sonnet | 4.6 Extended Thinking | 未測新版 | — | 留到下輪實測再對照 |
豆包 | 未測過 | 專家模式 | — | 首次登場,無對照基準 |
觀察 1:進化不是全面的,是分維度的。
四對完整對照裡,Claude Opus 跟 DeepSeek 都進化了,但進化的方向不一樣。Opus 4.7 進化在「擬人感」——讀起來更像作家寫的、刻意感更低。DeepSeek V4 進化在「深度」——伏筆更密、邏輯鏈更長。這代表使用者選 AI 寫小說時,不能只看「哪家最新」,要看「哪家的進化方向跟我需要的東西對得上」。
觀察 2:ChatGPT 的進化是反直覺的。
GPT-5.4 Thinking 到 5.5 Pro 研究等級,理論上是升級,但實測下來「思考時間變長」沒帶來「指令理解更準確」。反而因為思考過度,把簡單的「插一張圖」誤解成「描述要插的圖」。這是 OpenAI 在 Pro 訂閱方案上的取捨——研究等級思考適合複雜推理任務,但對「短文 + 簡單視覺需求」這種日常用法,可能不適合預設打開。
觀察 3:Grok 是這次最大的黑馬。
從 Grok 4.2 Expert 到 4.3,文字本身沒進步多少。但因為生圖指令是這次新加的,Grok 4.3 直接做到「文+圖一次到位」,領先其他家不只一個身位。這個進化是「從不能到能」的能力突破,不是「從 80 分到 90 分」的微調。身為 PM,我在團隊裡常講「能力突破比能力優化重要 10 倍」,這次 Grok 給了一個非常具體的例子。
觀察 4:Gemini 跟豆包是這次最讓人失望的。
Gemini Flash 3.5 跟豆包都有自家生圖引擎,網頁版也都支援生圖功能。但這次它們對「插入圖片」這句指令完全沒反應,等於把優勢藏起來。這不是能力問題,是工程設計問題——「自動觸發 vs 使用者手動切換」的判斷,兩家都選了後者。對追求「一次到位」的工作流來說,這個保守就是斷點。
整體判斷:AI 寫小說的「能力上限」這幾個月確實有進步,但進步幅度不像 2024 那波 GPT-4 跳到 GPT-4o、Claude 3 跳到 Claude 3.5 那麼大。這一輪更像是「分維度精修」——每家在自己擅長的方向繼續優化,而真正的能力突破(從不能到能),這次只發生在 Grok 的「複合指令執行力」這條線。
前一輪 6 款(2026 Q1)綜合評比
測完所有模型之後,我把各面向的表現整理成一張表:
評比維度 | GPT-5.4 Thinking | Claude Opus 4.6 | Claude Sonnet 4.6 | Gemini 3.1 Pro | Grok 4.2 Expert | DeepSeek V3.2 |
|---|---|---|---|---|---|---|
文字流暢度 | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★☆☆ |
情節連貫性 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
人物刻畫 | ★★★★☆ | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★☆☆ |
氛圍營造 | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★★★ | ★★★★★ | ★★★☆☆ |
創意獨特性 | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★★☆ | ★★★★★ | ★★★☆☆ |
對話自然度 | ★★★★☆ | ★★★★☆ | ★★★★★ | ★★★☆☆ | ★★★★★ | ★★★☆☆ |
生成速度 | ★★★☆☆ | ★★★☆☆ | ★★★★☆ | ★★★★☆ | ★★★★★ | ★★★★☆ |
幾個重點發現:Claude Opus 4.6 在文學品質上穩坐第一把交椅,但速度是它的硬傷。GPT-5.4 Thinking 是最均衡的全能型選手。Sonnet 4.6 的對話能力讓我印象最深,角色互動最有「人味」。Grok 4.2 在創意和速度上都拿到最高分,只是穩定性還要再磨。Gemini 的氛圍營造跟自帶解析這兩點很加分。DeepSeek V3.2 雖然整體墊底,但免費這張牌太實在了。
2026 復測這輪綜合評比(含 Opus 4.8 Max)
這輪復測的 6 款新模型,加上後續追測的 Opus 4.8 Max,我用同一套維度整理成一張表,方便跟上面前一輪那張直接對照。星等是依這輪實測的實際表現給的,純文字面向為主——Grok 4.3 的強項(文+圖一次到位)不在這幾個維度裡,所以它在這張表看起來不亮眼,要搭配前面的說明一起看。
評比維度 | Claude Opus 4.7 | Claude Opus 4.8 Max | ChatGPT 5.5 Pro | Gemini Flash 3.5 | Grok 4.3 | DeepSeek V4 | 豆包 |
|---|---|---|---|---|---|---|---|
文字流暢度 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ |
情節連貫性 | ★★★★★ | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★★★ | ★★★★☆ |
人物刻畫 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ | ★★★★☆ |
氛圍營造 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ |
創意獨特性 | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ | ★★★★☆ |
對話自然度 | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ |
生成速度 | ★★★☆☆ | ★★★☆☆ | ★☆☆☆☆ | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★★★ |
AI寫小說哪個模型最好?我的選擇建議
測完 12 款模型(前一輪 6 款 + 2026 復測 6 款),我整理出一份選擇指南,你可以根據自己的需求來挑。
追求文學品質、寫純文學或嚴肅文學→ Claude Opus 4.8 Max(4.7 Adaptive、4.6 Extended Thinking 也都很好)
Opus 系列的文字質感和敘事結構是目前所有 AI 裡最好的。最新的 4.8 Max 在埋伏筆、佈局一整章上又上一個台階,是這條線目前最強的一版;4.7 勝在放鬆自然,4.6 文藝腔最濃。那種「讀完一段會停下來回味」的感覺,只有 Opus 系列做得到。
需要均衡表現、什麼類型都能寫→ GPT-5.5 Pro 或 GPT-5.4 Thinking
GPT 系列各方面都沒有明顯短板,是最安全的選擇。GPT-5.5 Pro 研究等級思考適合長篇複雜結構、多人物多線敘事;GPT-5.4 Thinking 則適合快速試水溫、節奏比較輕快。
寫網文、需要快節奏和大量產出→ Claude Sonnet 4.6 或 豆包專家模式
Sonnet 4.6 Extended Thinking 速度快、節奏好、對話超自然,非常適合連載型的網路小說。豆包專家模式中文網文風格更貼近中文母語讀者口味,反應速度也快上百倍(思考 16 秒 vs Sonnet 幾分鐘)。
需要紮實的世界觀設定→ Gemini 3.1 Pro(Flash 3.5 略遜)
如果你的小說類型是奇幻、科幻這種很吃設定的題材,Gemini 在場景建構和背景鋪陳上有天然優勢。Gemini 3.1 Pro 比 Flash 3.5 細膩,加上它自帶構思解析,等於一邊寫一邊教你;Flash 3.5 比較適合快節奏網文,世界觀深度稍打折。
想要突破框架、找靈感→ Grok 4.2 Expert
速度快到離譜,文字風格有自己的辨識度,適合已經有寫作經驗、想找不同切角的創作者。
需要文+圖一次到位的工作流→ Grok 4.3
這次的最大黑馬,六家裡唯一達成「一個提示詞、文字+圖一次到位」的模型。圖片對齊細綱 80%。文字本身平庸,但複合指令執行力遠遠領先其他家。寫社群短篇、需要配圖的網文作者,Grok 4.3 目前是唯一選擇。
伏筆吃重、推理懸疑類型→ DeepSeek V4 專家模式
資訊密度六家最高,伏筆編織能力最強,邏輯連貫性極佳。它把細綱裡所有要素都塞進去、連隨手寫的詞都能成為關鍵伏筆。寫懸疑、推理、推理向小說最適合。
中文網文 + 快速產出 + 零成本→ 豆包專家模式
中文審美最在地、章節命名最有畫面感(這次它的「灰度碰撞」是六家最有意境的章節名),免費可用。注意兩岸版本差異——大陸版跟海外版的訓練資料和審查邊界不同。台灣使用者連 doubao.com 通常能直接用。
預算有限、想先試水溫→ DeepSeek V4 或 豆包
兩家都完全免費(網頁版專家模式不用付錢)。DeepSeek V4 比之前的 V3.2 進步明顯,伏筆編織能力上一個台階;豆包在中文流暢度上有母語優勢,加上速度極快,初心者試水溫推這兩家。
還是不確定的話,這個快速判斷表給你:
你的情境 | 推薦模型 | 大概要花多少錢 | 下一步 |
|---|---|---|---|
文學向短篇、追文字質感 | Claude Opus 4.8 Max | Claude 訂閱方案 | 到 Claude 官網開訂閱,主力用 4.8 Max |
長篇連載、複雜結構 | ChatGPT 5.5 Pro | $200/月(Pro 訂閱) | 先用 Plus 月費 $20 試水溫,習慣了再升 Pro |
網文短篇、追快速產出 | Gemini Flash 3.5 或 Sonnet 4.6 | $20/月 | 用 Gemini 免費版試手感,付費版再上 Pro |
文+圖一次到位工作流 | Grok 4.3 | $30-40/月(SuperGrok) | 免費版先試生圖能力,再決定要不要訂 |
零預算入門、伏筆吃重 | DeepSeek V4 | 完全免費 | 直接到 chat.deepseek.com 註冊就能用 |
中文網文、要快要免費 | 豆包 | 完全免費 | 到 doubao.com 註冊,注意兩岸版本差異 |
什麼情況我會直接告訴你「先不要」:
- 如果你連故事框架都還沒想清楚,就想找一個 AI 幫你「從零到一寫一篇小說」——任何模型都救不了你,先把故事框架想清楚再來
- 如果你期待 AI 幫你寫出「能直接出版」的成品——目前所有模型都還在 80 分階段,最後 20 分還是要你自己潤色
- 如果你不想花時間調提示詞,期待「一句話搞定」——這次實測連最厲害的 Grok 都只做到 80% 對齊細綱,剩下 20% 還是要你手動修
幾個我踩過的坑,先幫你避掉
做這兩輪測試的過程中,我也踩了不少坑,這邊一起分享:
坑一:prompt 別寫得太死。我一開始給的細綱非常詳細(章數目標、阻礙、轉折、線索、伏筆全部寫好了),結果發現有些模型幾乎是「照翻」我的大綱,反而失去了創意發揮的空間。後來我留了一些「模糊地帶」,模型的表現立刻好了一截。有趣的是 Grok 最不受 prompt 約束,它就是要按自己的想法來。
坑二:Thinking 模式不是萬靈丹。這些推理模式在寫小說的時候確實能帶來更完整的結構佈局,但也會讓文字變得「太理性」。GPT-5.4 想了 19 秒寫出來的東西很完整,但少了點靈氣。這次復測的 ChatGPT 5.5 Pro 研究等級思考更是極端例子——7 分多鐘的思考,反而把簡單的「插一張圖」誤解成「描述要插的圖」。思考越久不等於越準。
坑三(2026 復測新發現):複合指令 ≠ 模型自動執行。我這次特意把「插入一張圖片」放在提示詞第二句最顯眼位置。結果六家裡只有 Grok 4.3 真正觸發生圖工具。Gemini 跟豆包自己有生圖引擎卻沒主動觸發;ChatGPT 想太多搞錯方向;Claude 沒生圖能力但會搜替代圖。要 AI 跑複合工作流,現階段別期待「一句話搞定」,要明確切換到對應工具。
坑四(2026 復測新發現):付費版不見得永遠贏免費版。我這次幾乎所有家都訂了 Pro 方案,但實測下來 DeepSeek 跟豆包這兩個免費版居然表現都不錯——DeepSeek 伏筆編織能力最強、豆包中文網文審美最在地。如果你預算有限,先試免費版反而可能比直接訂閱付費版更划算。
結語
2026 年的 AI 寫小說工具,已經從「堪用」進化到「好用」。這兩輪測試最深刻的感受是:模型之間的「性格差異」越來越明顯。
前一輪:Opus 文藝、Sonnet 俐落、GPT 穩健、Grok 狂放、Gemini 細膩、DeepSeek 務實。
2026 復測:Opus 一路升到 4.8 Max、伏筆編織與整章佈局最強,ChatGPT 5.5 Pro 思考過度、Gemini Flash 3.5 直球快節奏、Grok 4.3 從零到一突破文+圖、DeepSeek V4 伏筆密度爆表、豆包中文審美最在地。
12 個風格完全不同的寫手。但這兩輪實測讓我看到一個更深的訊號:「文字品質」跟「複合指令執行力」是兩個會分流的維度。寫純文字小說,Opus / ChatGPT / 豆包都行;但要「一個 AI 跑完整篇章(含配圖)」的工作流,目前只有 Grok 4.3 走通。想看同一批 AI 在其他任務上的差距,可以對照:純編程跟 Agent 工作流的旗艦對打看 GPT-5.5 vs Claude Opus 4.7 全方位對決;含中文字海報跟商業圖看 ChatGPT Images 2 vs Midjourney vs Grok Imagine 三巨頭實測;訂閱前想看付費版差別則看 Claude/ChatGPT/Gemini 三大付費 AI 完整比較;先用免費版起步可看 2026 年最值得試的 8 款免費 AI 工具,一次補齊「寫作/編程/生圖/訂閱選擇」四個面向。
工具再好,最終決定一部小說好不好看的,還是創作者本身的審美和判斷力。AI 能幫你快速產出初稿、突破靈感瓶頸、在你卡關時提供意想不到的切角。但那個讓讀者忍不住翻到下一頁的魔力,來自於你——一個真正理解故事、理解人性的人。
順帶一提,這對被 12 款 AI 反覆重寫初次相遇的男女主角——江瀾跟陸沉——本來只是隨手做的細綱,被十幾個版本反覆呈現後,反而越來越有血肉。也許之後可以真的把他們寫成完整故事,畢竟提示詞我已經測得熟透了。
你的下一步:從讀完這篇到真的試試看
讀完這篇你已經對 12 款 AI 寫小說模型的差別有完整概念了,但「知道」跟「用過」是兩件事。我建議你按這個順序走,省下不必要的訂閱費和踩雷時間。
第一步:零成本試手感(這週就能做)
- 先到 DeepSeek 官網跑一段,看看 AI 寫小說的最低門檻是什麼樣
- 用同樣的提示詞到 豆包官網跑一次,比較中文母語 vs 國際模型的差異
第二步:付費選一家深耕(試完免費版後)
- 追文字質感 → Claude Pro 訂閱,主力用 Opus 4.7
- 追文+圖一次到位 → SuperGrok 訂閱,主力用 Grok 4.3
- 追長篇連載 → ChatGPT Pro 訂閱,但先用 Plus 月費試水溫
第三步:建立你自己的提示詞模板
實測完幾家後,你會發現好的提示詞比好的模型重要。我這次用的細綱式提示詞,你可以直接拿去用、自己改。寫小說不是丟一句「寫一篇愛情小說」就完事,細綱越具體、AI 寫出來的東西就越貼近你想要的——也歡迎你自己換主角、換場景,創造你自己版本的「江瀾陸沉初次相遇」。
歡迎到 關於夜羽凌 看看我其他 AI 工具實測,或訂閱我的部落格,會不定期收到信。
寫小說只是其中一個用途,想把每家的模型整包、日常該怎麼選搞清楚?我各寫了一篇選型對比:ChatGPT 模型選型全攻略、Claude 模型怎麼選(Opus、Sonnet、Haiku)、Gemini 模型怎麼選(Pro、Flash、Flash-Lite)。
常見問題(FAQ)
2026年AI寫小說哪個模型最好?
看你要寫什麼。追求文學品質選 Claude Opus,三代裡最新的 4.8 Max 伏筆編織最強、4.7 最自然、4.6 最文藝;要長篇結構選 GPT-5.5 Pro;寫中文網文選豆包或 Sonnet 4.6;預算有限挑免費的 DeepSeek V4。沒有單一冠軍,先確定類型再選。
AI寫小說跟人類作家差距還大嗎?
2026 年的 AI 寫小說工具已從「堪用」進化到「好用」,節奏、角色塑造、中文表達都明顯進步,最新的 Claude Opus 甚至能自己佈局一整章的伏筆。不過 AI 初稿仍需人工潤色,從 80 分推到 95 分的最後一段路,還是得創作者自己走完。
有免費的AI寫小說工具嗎?
有。DeepSeek V4 和豆包的網頁版專家模式都完全免費。DeepSeek V4 伏筆密度最高、邏輯連貫,適合推理懸疑;豆包中文最順、思考只要 16 秒。零預算想試 AI 寫小說,先從這兩家入手最划算。
用AI寫小說需要什麼技巧?
三個關鍵技巧:一、prompt 不要寫得太死,留一些模糊地帶讓 AI 發揮創意;二、Thinking/研究等級思考不是萬靈丹,想太久反而把簡單需求(例如「插一張圖」)搞複雜;三、別指望一次到位,AI 給的是高品質初稿,最後的潤色和改寫仍要創作者自己完成。
ChatGPT和Claude寫小說哪個比較好?
看用途。要長篇、多線、結構複雜選 ChatGPT(GPT-5.5 Pro 研究等級思考結構最穩);要文字質感、人物與氛圍選 Claude Opus(最新 4.8 Max 文藝感與伏筆最強);對話多、節奏快的網文,Claude Sonnet 4.6 最自然。沒有絕對贏家,看你寫哪一種。
豆包寫小說真的能用嗎?跟 Claude 比差在哪?
豆包專家模式對中文網文很有優勢,特別是中文字詞的雙關、意象敏感度。這次它的「灰度碰撞」章節名是六家裡最有畫面感的。但豆包沒主動觸發生圖,而且台灣使用者要適應簡體訓練資料的偏好。跟 Claude Opus 4.7 比,豆包贏在中文在地審美跟速度(思考 16 秒 vs Opus 幾分鐘);輸在文字節制感跟留白功力。中文網文選豆包,文學向短篇選 Opus。
AI 寫小說能一次同時生出文字跟圖片嗎?
2026 年的現在,只有 Grok 4.3 做到「一個提示詞、文字+圖一次到位」。其他家不是沒能力(Gemini、豆包、ChatGPT 都有生圖引擎),是「指令理解力」沒打通——它們不會因為對話裡出現一句「插入圖片」就自動切換到生圖模式。要它們生圖,目前還是要明確切到生圖介面。
跟上次測比,2026 這版 AI 寫小說真的進步很多嗎?
分維度看。文字品質有進步,但幅度不像 2024 那波 GPT-4 跳到 GPT-4o 那麼大。Claude Opus 進步在「擬人感」與「伏筆佈局」;DeepSeek 進步在「伏筆深度」;ChatGPT 思考更深但反而過度解讀;Grok 突破在「複合指令執行力」。這一輪是分維度精修,不是全面跳級。選 AI 寫小說要看「進化方向跟你需要的東西對不對得上」。
延伸閱讀
- ChatGPT vs Claude vs Gemini:2026 中文寫作到底該選誰? — FuturePicker
- 怎麼與 ChatGPT 合寫小說?5 個技巧,AI 也能寫出好東西 — 數位時代
- 推薦 4 款免費的 AI 續寫網站:用 AI 續寫來創作小說 — GenApe
- 中文 AI 寫作工具比拼:7 款產生器推薦 — HK01
- GPT-5.3-Codex vs Claude Opus 4.6 同日發布背後的恩怨 — 知乎專欄



