💡 核心結論速覽 (TL;DR)
- 一句話:Opus 4.7 不是玩噱頭,是實打實的一輪升級,5 大重點在編程、視覺推理、文件推理、生物分子推理與 Adaptive Thinking。
- 跑分跳幅:編程 58%→70%(CursorBench)、視覺推理 69.1%→82.1%(CharXiv)、文件推理 57.1%→80.6%、生物分子推理翻約 2.4 倍。
- 體感差異:Adaptive Thinking 取代 Extended Thinking、加上 effort level 效率提升,用起來更流暢。
- 誰升最有感:每天寫程式、讀長文件、做研究的人;只是聊天問答的人感受有限。
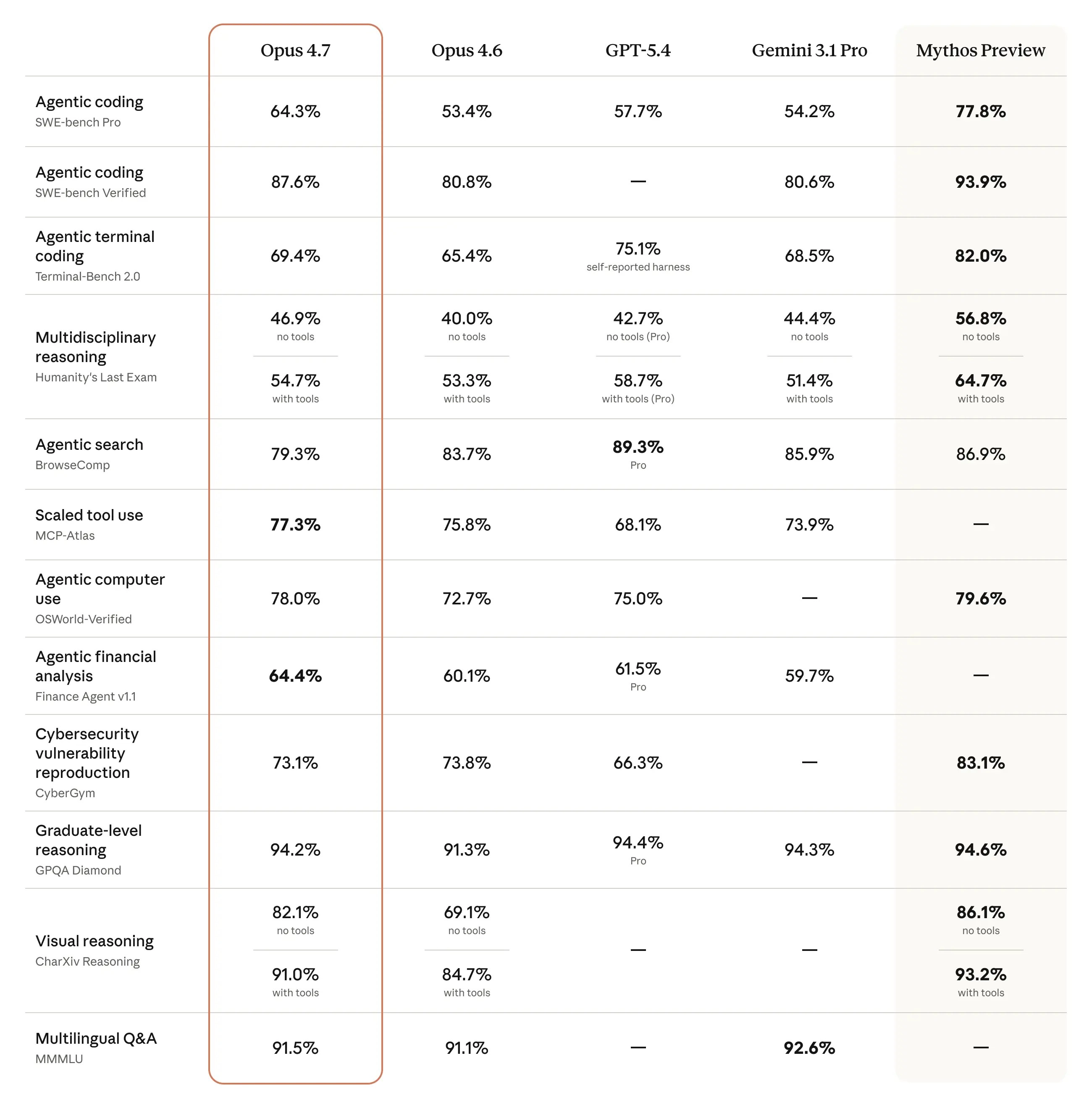
Claude Opus 4.7 到底升級了什麼?一張表看懂
先上硬數據。Opus 4.7 在編程、視覺、推理這三塊都有明顯提升,底下是官方公佈的 benchmark 對比:
項目 | Opus 4.7 | Opus 4.6 | 提升幅度 |
|---|---|---|---|
SWE-bench Verified(編程基準) | 87.6% | 80.8% | +6.8 個百分點 |
SWE-bench Pro(進階編程) | 64.3% | 53.4% | +10.9 個百分點 |
CursorBench(編程基準測試) | 70% | 58% | +12 個百分點 |
Rakuten-SWE-Bench(真實生產環境) | 3x 解決率 | 基準 | 300% 提升 |
視覺推理 CharXiv Reasoning(無工具) | 82.1% | 69.1% | +13 個百分點 |
OfficeQA Pro(文件推理) | 80.6% | 57.1% | +23.5 個百分點 |
知識工作 Elo(GDPVal-AA) | 1753 | 1619 | +134 分 |
生物分子推理 | 74.0% | 30.9% | +43.1 個百分點(2.4 倍) |
長上下文推理(GraphWalks BFS 1M) | 58.6% | 41.2% | +17.4 個百分點 |
金融模組評分 | 0.813 | 0.767 | +6% |
長期連貫性(Vending-Bench 2) | $10,937 | $8,018 | +36% |
有幾個數字我覺得特別有意思。CursorBench 從 58% 跳到 70%——用 Claude 寫程式的人,實際體感會差很多,尤其是那種要跨多個檔案、理解整個 codebase 的複雜任務。
另一個我覺得蠻猛的是視覺推理。CharXiv Reasoning 從 69.1% 拉到 82.1%(+13pp),搭配工具再拉到 91.0%。生物分子推理這塊從 30.9% 直接翻到 74.0%,快要 2.4 倍,對做科研的朋友來說算是很有感的跳級。
文件推理這一塊,OfficeQA Pro 的正確率從 57.1% 拉到 80.6%,比 GPT-5.4 的 51.1%、Gemini 3.1 Pro 的 42.9% 高出不少——白話說就是,Claude 在處理企業文件、合約、報表這類任務上,已經把對手甩開一段距離。
重點整理:Opus 4.7 的升級不是單點突破,而是多點一起動——編程(+13%)、視覺推理(+13pp)、文件推理(80.6% 正確率)、生物分子推理(2.4 倍)、長上下文推理(+17.4pp),而且 API 定價完全不變。
編程能力提升:寫 Code 的人最該關注的升級
Opus 4.7 在編程這塊的進步,是這次更新最有感的地方。根據 Anthropic 官方數據,在 93 項編程基準測試中,Opus 4.7 比 Opus 4.6 提升了 13%,其中包含 4 項前代模型完全無法解決的任務。
翻譯成白話:Opus 4.7 能啃的程式邏輯變複雜了。
我自己的體感是,Opus 4.6 在修單一檔案的 bug 沒什麼問題,但一旦要跨多個檔案、看懂整個專案架構,就偶爾會走歪。Opus 4.7 在 Rakuten-SWE-Bench 上的表現——真實生產問題解決率拉了 3 倍——剛好打在這個痛點上。
更有感的是 effort level 的效率提升。官方內部測試數據顯示,Opus 4.7 在 high effort level 下的表現(約 65.5%),就已經超過 Opus 4.6 開到 max effort level 的成績(約 61%)。
也就是說,你花更少的 tokens 就能拿到更好的結果。
在 max effort 下,Opus 4.7 更是衝到約 75%,比 Opus 4.6 高出 14 個百分點。
實際在用的團隊給出的反饋也差不多。Notion Agent 團隊說 Opus 4.7 比 Opus 4.6 高了 14%,而且用了更少的 tokens、工具調用錯誤還少了三分之一。Hex 團隊則說,低 effort 的 Opus 4.7,差不多等於中 effort 的 Opus 4.6。
另外,Claude Code 也跟著更新了幾個實用功能:
/ultrareview 指令:專門用來做程式碼審查,不用再自己寫一大串提示詞請 AI 幫你 code review
所有方案預設 effort level 提升至 xhigh:這是新增的一個介於 high 和 max 之間的等級,讓你可以更細緻地控制 AI 投入多少算力來思考
Max 用戶解鎖自動模式(Auto Mode):減少人工介入,讓 Claude Code 更自主地完成任務
再補一組數據:SWE-bench Multilingual(多語言編程)從 77.8% 拉到 80.5%;SWE-bench Multimodal(含圖片理解的編程任務)從 27.1% 跳到 34.5%,後者的提升幅度超過 27%,對要處理截圖、UI 設計稿的前端工程師會特別有感。
如果你是每天都在用 AI 寫程式的開發者,光是 CursorBench 從 58% 跳到 70% 這一下,就值得花幾分鐘切換過去試試。
視覺能力升級:看圖、看文件、看螢幕都更強
老實說,這塊是我自己最期待的升級。
之前用 Opus 4.6 分析圖表或技術圖的時候,偶爾會出現讓人哭笑不得的錯誤——數字看錯、表格欄位搞混、小字直接忽略。在 CharXiv Reasoning(視覺推理基準)上,Opus 4.6 也只拿 69.1%,確實還有不少進步空間。
Opus 4.7 把這個數字拉到了 82.1%(+13pp),搭配工具使用再到 91.0%。而 XBOW 的電腦操作場景下,visual acuity(視覺敏銳度)從 54.5% 飆到 98.5%——這個數字是 XBOW 自家 CEO 實測後丟出來的。
除了準確率的跳躍,圖片處理本身也變強了。Opus 4.7 能接受最高 2,576 像素長邊的圖片,大約 375 萬像素,比之前多了 3 倍有餘。換個說法就是,你可以直接丟一張解析度很高的財報截圖、產品規格表、甚至手寫筆記進去,不用再擔心被壓到 AI 看不清楚小字。
在視覺導航測試 ScreenSpot-Pro 上,搭配高解析度圖片跟工具使用,Opus 4.7 拿到 87.6% 的準確率,連沒用工具也有 79.5%。這對要讓 AI 操作電腦介面、或做 GUI 自動化測試的人來說蠻重要的。
這對幾類人特別有幫助:
財務分析師:直接截圖財報讓 AI 提取數據,不用手動輸入。OfficeQA Pro 文件推理正確率從 57.1% 提升到 80.6%,遠超 GPT-5.4 的 51.1%
產品經理:截圖競品介面讓 AI 分析,或者拍照白板內容讓 AI 整理成文字
研究人員:論文中的圖表、數據視覺化、甚至化學分子結構和技術圖表,都能更精確地被 AI 理解。生物分子推理從 30.9% 提升到 74.0%,是所有 benchmark 中提升最誇張的
重點整理:視覺推理 CharXiv 從 69.1% → 82.1%(+13pp),搭配 3 倍圖片解析度支援和 ScreenSpot-Pro 87.6% 的視覺導航成績,加上 XBOW 電腦操作場景的 98.5% 視覺敏銳度,Claude 終於可以在「看圖」和「看螢幕操作」這兩件事上被信任了。
推理和指令遵循:不再「自作聰明」
你有沒有遇過這種情況:明明跟 AI 說「字數控制在 500 字以內」,結果它洋洋灑灑寫了 2000 字?或者你給了很明確的格式要求,它偏偏要按自己的方式來?
Opus 4.7 在指令遵循這塊做了「顯著改進」(官方用語,不是我自己講的)。實際用起來,有幾個地方特別有感:
長上下文推理更穩定:在 GraphWalks 長上下文基準測試中,100 萬 tokens 下的 BFS 任務正確率從 41.2% 提升到 58.6%,Parents 任務從 71.1% 提升到 75.1%。處理超長文件或多輪對話時,不會在後半段「忘記」前面的要求
知識工作能力領先:在 GDPVal-AA(衡量經濟價值知識工作的 benchmark)中,Opus 4.7 以 Elo 1753 分排名第一,超過 GPT-5.4 的 1674 分和 Opus 4.6 的 1619 分
長期連貫性明顯變好:Vending-Bench 2(模擬長時間自主運行的商業任務)成績從 $8,018 提升到 $10,937,增幅 36%。Cognition 團隊(開發 Devin 的公司)表示 Opus 4.7 能連續工作數小時而保持連貫
指令遵循更精確:官方特別指出,Opus 4.7 會「按字面意思」理解你的指令,不再像以前一樣自作主張。這是好事,但也意味著你的 prompt 需要寫得更精準
對需要 AI 做複雜分析、或跑長專案規劃的人,這是很實際的幫助。我之前用 Opus 4.6 做長文任務時,常常要在中段再回頭提醒它一次最開始約定好的格式跟要求,不然它就會自己飄。Opus 4.7 在長上下文 benchmark 的數據,確實好看很多。
像我把 Claude 用在內容工作上的流程,之前就寫在 Claude 寫 SEO 文章的完整工作流 這篇,Opus 4.7 在指令遵循變穩之後,那套流程會跑得更順。
另一個用起來明顯有感的改動:Opus 4.7 把以前的「Extended Thinking」(延伸思考)換成了「Adaptive Thinking」(自適應思考)。
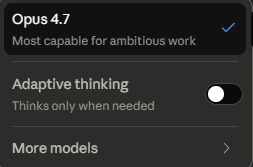
以前 Opus 4.6 和 Sonnet 4.6 的 Extended Thinking 要你手動開啟,開了之後不管什麼問題都會花更多時間慢慢想。Opus 4.7 的 Adaptive Thinking 則是「需要的時候才啟動深度思考」——簡單的問題快快答、複雜的問題才把深度推理拉起來。
結果就是回應速度跟 token 消耗都變得合理多了。
📌 重點整理:長上下文 BFS 推理 41.2%→58.6%、知識工作 Elo 排名第一(1753 分)、長期連貫性 +36%,加上 Adaptive Thinking 取代 Extended Thinking,讓 Opus 4.7 在推理和指令遵循上都往上拉了一階。
不過要提醒一點:因為 Opus 4.7 對指令的理解變得更「字面」了,如果你之前的 prompt 寫得比較隨意或含糊,可能需要重新調整。官方也建議現有的自動化流程升級前先做測試。
想瞭解三家 AI 在推理能力上的差異,可以看看我們的Claude、ChatGPT、Gemini 三大付費 AI 比較。
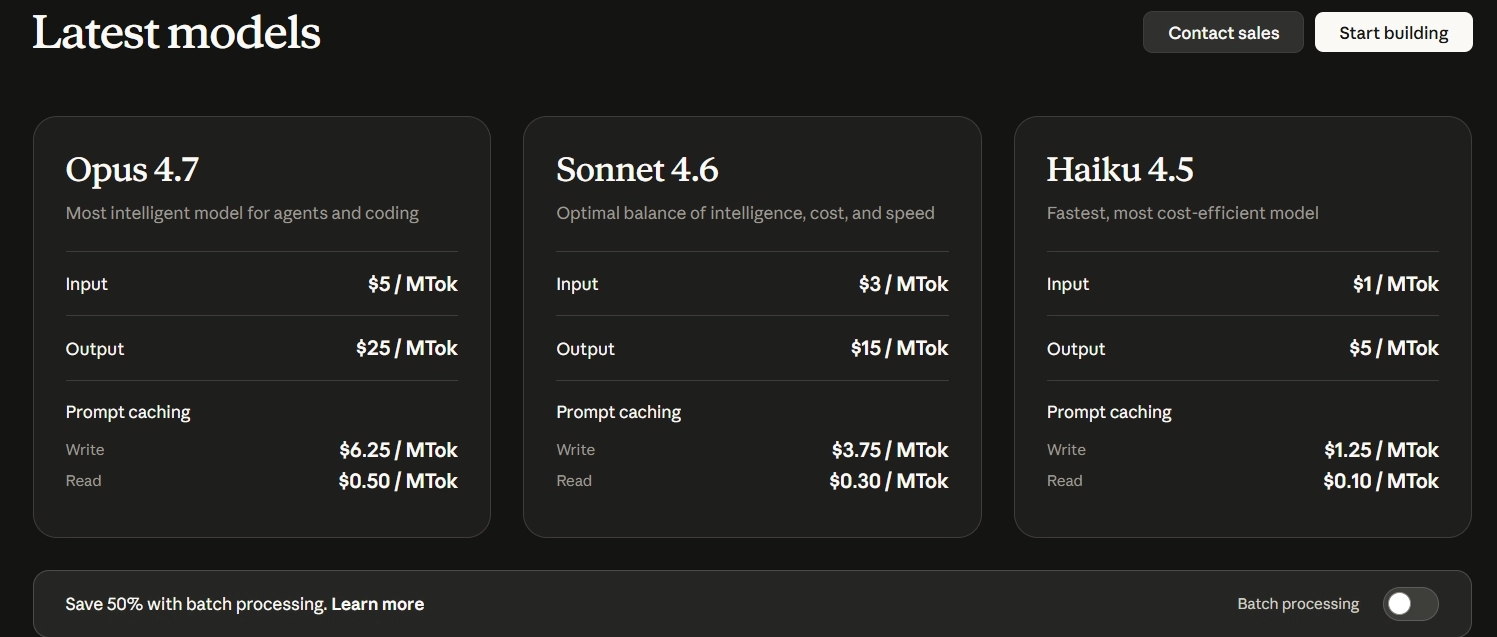
定價與方案:價格沒變,性能更強
這大概是最讓人開心的消息了:Opus 4.7 的 API 定價跟 Opus 4.6 完全一樣。
項目 | Opus 4.7 / 4.6 | Sonnet 4.6 | Haiku 4.5 |
|---|---|---|---|
輸入價格 | $5 / 百萬 tokens | $3 / 百萬 tokens | $1 / 百萬 tokens |
輸出價格 | $25 / 百萬 tokens | $15 / 百萬 tokens | $5 / 百萬 tokens |
Prompt 快取寫入 | $6.25 / 百萬 tokens | $3.75 / 百萬 tokens | $1.25 / 百萬 tokens |
Prompt 快取讀取 | $0.50 / 百萬 tokens | $0.30 / 百萬 tokens | $0.10 / 百萬 tokens |
批次處理折扣 | 節省 50% | 節省 50% | 節省 50% |
上下文窗口 | 100 萬 tokens | 100 萬 tokens | 100 萬 tokens |
(以上 Sonnet 4.6 和 Haiku 4.5 定價為截至 2026 年 4 月的參考數據,實際價格請以 Anthropic 官方定價頁 為準。)
不過有個眉角要注意:Opus 4.7 換了新的分詞器(tokenizer),同樣的輸入文字會多吃 1.0 到 1.35 倍的 tokens。再加上高 effort level 下,模型會產生更多思考 tokens,所以帳單上的實際花費,會比 Opus 4.6 稍微多一點點。
好消息是,把 Prompt 快取讀取($0.50/百萬 tokens,只有標準輸入價格的十分之一)用好,重複查詢的成本可以壓得很低。
如果你是 Claude Pro 或 Max 的訂閱用戶,直接就能用 Opus 4.7,不需要額外付費。Team 和 Enterprise 方案也同步支援。
在哪裡可以用?
Opus 4.7 同步上線了下面這幾個平台:
Claude.ai(網頁版和 App)
Anthropic API
Amazon Bedrock
Google Cloud Vertex AI
Microsoft Foundry
如果你還在猶豫要不要從 Sonnet 4.6 升級到 Opus,可以參考這篇Claude Opus 與其他旗艦模型的實測比較,看看 Opus 等級的模型在實際任務中到底強在哪裡。
Opus 4.7 跟 GPT-5.4、Gemini 3.1 Pro 比起來呢?
這是很多人最想問的問題。直接說結論:在編程領域,Opus 4.7 目前是最強的。
先看最核心的 SWE-bench Verified(業界最常用的編程 benchmark):Opus 4.7 拿下 87.6%,Opus 4.6 是 80.8%,提升了將近 7 個百分點。同場競技的 Gemini 3.1 Pro 是 80.6%,被明顯甩開。
在 SWE-bench Pro 上差距更大:Opus 4.7 的 64.3% 遠超 GPT-5.4 的 57.7% 和 Gemini 3.1 Pro 的 54.2%。
但是——Opus 4.7 並不是所有項目都拿第一。
根據官方公佈的完整 benchmark 表,各家在不同任務上互有勝負:
測試項目 | Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro | 誰最強? |
|---|---|---|---|---|
SWE-bench Verified(編程) | 87.6% | — | 80.6% | Opus 4.7 |
SWE-bench Pro(進階編程) | 64.3% | 57.7% | 54.2% | Opus 4.7 |
Terminal-Bench 2.0(終端編碼) | 69.4% | 75.1% | 68.5% | GPT-5.4 |
BrowseComp(搜尋能力) | 79.3% | 89.3% | 85.9% | GPT-5.4 |
Humanity's Last Exam(多學科推理,有工具) | 54.7% | 58.7% | 51.4% | GPT-5.4 |
GPQA Diamond(研究生級推理) | 94.2% | 94.4% | 94.3% | 三家幾乎打平 |
OSWorld(電腦操作 Agent) | 78.0% | 75.0% | — | Opus 4.7 |
Finance Agent(金融分析) | 64.4% | 61.5% | 59.7% | Opus 4.7 |
CharXiv(視覺推理,無工具) | 82.1% | — | — | Opus 4.7 |
簡單講:Opus 4.7 在編程、Agent 任務、視覺推理這三塊有明顯優勢;GPT-5.4 在終端編碼、網路搜尋、多學科推理更吃香;Gemini 3.1 Pro 則在多語言 QA(MMMLU 92.6%)上略勝一籌。
所以要怎麼選,真的看你平常最常做什麼。寫程式、跑 Agent?選 Opus 4.7;需要強搜尋能力?GPT-5.4 目前更穩。
想看更完整的三家比較,推薦閱讀Claude、ChatGPT、Gemini 三大付費 AI 怎麼選這篇,裡面有更詳細的功能對比和購買建議。
安全性與對齊:Opus 4.7 表現如何?
先講安全性。官方的 Misaligned behavior(不對齊行為)測試,分數越低越好:Mythos Preview 最優(約 1.78)、Opus 4.7 第二(約 2.46)、Sonnet 4.6(約 2.52)、Opus 4.6(約 2.75)排在後面。
也就是說,Opus 4.7 在安全對齊上比前代有進步,欺騙、諂媚這類問題行為的頻率都降了。
不過官方也老實說,Opus 4.7 在「受管制物質的減害建議」方面有輕微弱點。他們自己給的整體評價是「大致對齊且可信賴,但尚未完全理想」——這種誠實的自我評價,我反而覺得比一味宣傳「最安全」來得可信。
Claude Mythos 是什麼?為什麼 Anthropic 不敢放出來?
你可能在一些新聞裡看到「Claude Mythos」這個名字。簡單說,Mythos 是 Anthropic 內部一個比 Opus 4.7 更強大的模型,但因為網路安全方面的疑慮,目前沒有對外公開。
根據報導,Anthropic 覺得 Mythos 的能力已經強到要做更嚴格的安全評估才能放出來;Opus 4.7 的網路安全能力則是刻意被限制在 Mythos 之下,所以才會被定位成「商業替代方案」——夠強,也夠安全。
這其實蠻符合 Anthropic 一直以來的風格:寧可慢一點,也不想在安全性上妥協。不管你怎麼看這個策略,至少能看出 Opus 4.7 背後還有更強的技術儲備,接下來的升級空間蠻值得期待的。
常見問題 FAQ
Opus 4.7 和 Opus 4.6 最大的差別是什麼?
最明顯的差別有五塊:編程能力整體上來(93 項任務整體 +13%、CursorBench 58%→70%、SWE-bench Verified 80.8%→87.6%)、視覺推理 CharXiv 69.1%→82.1%(+13pp)、OfficeQA Pro 文件推理正確率 57.1%→80.6%、生物分子推理 30.9%→74.0%(2.4 倍)、長上下文 BFS 推理 41.2%→58.6%。
另外思考模式從 Extended Thinking 改為 Adaptive Thinking,回應也更直接。定價維持不變,等於白賺一次升級。
Opus 4.7 要另外付費嗎?
不用。如果你已經是 Claude Pro($20/月)、Max($100 或 $200/月)、Team 或 Enterprise 的訂閱用戶,直接就能使用 Opus 4.7。API 用戶的定價也跟 Opus 4.6 相同:輸入 $5/百萬 tokens、輸出 $25/百萬 tokens。
我該從 Sonnet 4.6 升級到 Opus 4.7 嗎?
看你的需求。如果你主要是用 AI 做簡單的文字對話、翻譯、摘要,Sonnet 4.6 的性價比更高(價格大約是 Opus 的 1/5)。但如果你要寫複雜程式碼、分析大量文件、或跑自動化 Agent,那 Opus 4.7 跟 Sonnet 的能力差距會拉得非常明顯。
還在猶豫每個月 AI 訂閱值不值這筆錢的話,可以順便看一下 每月付費 AI 工具盤點:哪些 AI 訂閱值得續訂 這篇,會幫你把帳算清楚。
Claude Opus 4.7 的上下文窗口有多大?
100 萬 tokens,跟 Opus 4.6 一樣。這大約等於 75 萬字的中文,或者一整本長篇小說的內容。
Opus 4.7 可以在 Amazon Bedrock 和 Google Vertex AI 上用嗎?
可以。Opus 4.7 同步上線了 Anthropic API、Amazon Bedrock、Google Cloud Vertex AI 和 Microsoft Foundry,企業用戶可以在自己習慣的雲端平台上直接使用。
結語
Claude Opus 4.7 給我的感覺是——Anthropic 這次沒在玩噱頭,而是實打實做了一輪升級。
編程從 58% 跳到 70%(CursorBench)、視覺推理從 69.1% 拉到 82.1%(CharXiv)、文件推理正確率從 57.1% 衝到 80.6%、生物分子推理直接翻了 2.4 倍,再加上 Adaptive Thinking 取代 Extended Thinking,用起來流暢不少。
加上 effort level 的效率提升,等於同樣的任務花更少 tokens 就能拿到更好的結果。
當然,它也不是沒缺點——在終端編碼和網路搜尋上被 GPT-5.4 壓一頭,指令遵循方式變了之後,舊 prompt 可能要回頭調一下。但以這次的升級幅度來說,算是讓人願意繼續用下去的那種。
最良心的是價格完全沒漲。在各家 AI 公司都在想辦法調高價格的 2026 年,Anthropic 這一手真的讓人舒服。
如果你已經在用 Claude,幾乎沒有理由不切到 Opus 4.7 試試;如果你還在觀望,這波升級會是個不錯的切入點。預算卡得比較緊、想先從免費的東西試起也沒問題,我整理過一份 2026 年最值得試的 8 款免費 AI 工具,可以先從這裡下手,之後再決定要不要升到付費版。
我後面有發一篇 Opus 4.7 、Opus 4.6 和 Sonnet 4.6的完整實測文章,用具體任務對比 Opus 4.6 和 Sonnet 4.6 的表現差異,記得去看看。
延伸閱讀:
Claude、ChatGPT、Gemini 三大付費 AI 到底怎麼選?2026 最新購買建議
Claude Opus 4.5、GPT-5.1、Gemini 3 Pro 比較:實測後告訴你怎麼選


