💡 核心結論速覽 (TL;DR)
- 一句話:Opus 4.7 在視覺理解、編程確實贏 Opus 4.6,但不是「打遍天下無敵」——台灣商業分析題反而被 Sonnet 4.6 反超。
- 三次實測平均:Opus 4.7 = 89、Sonnet 4.6 = 84.3、Opus 4.6 = 84(4.7 平均最高,但有一次被 Sonnet 反超)。
- 官方跑分:CharXiv 視覺推理 +13、SWE-bench Pro +10.9、Terminal-Bench +4 個百分點。
- 怎麼用:別無腦升最貴的——每個模型有擅長區,照任務(視覺/編程 vs 商業分析)挑模型。
Claude Opus 4.7 在視覺理解和編程任務上真的贏過 Opus 4.6,但在台灣商業分析題目上,反而被 Sonnet 4.6 反超。三個實測跑完,我的結論不是「一定要升級最貴的」,而是每個模型有自己的擅長區,沒有一個打遍天下無敵手。
下面這篇是我花一個晚上做的三次實測記錄,請你準備好心理準備,因為有些結果滿顛覆直覺的。
開測那晚,Opus 4.7 剛發布。我看到官方的 benchmark 數字:CharXiv 視覺推理 +13 個百分點、SWE-bench Pro +10.9 個百分點、Terminal-Bench +4 個百分點(5 大升級重點整理在這篇),帳面上是一次跳躍式進化。
但好奇歸好奇,benchmark 是一回事,拿來做工作又是另一回事。我想知道這些百分點在我的真實情境裡會剩下多少差距,所以當晚就開測了。
於是我設計了三個任務:複雜財報圖片理解、React 編程、台灣商業分析。三個模型同場較勁,每個錯誤我都回頭核對原始資料,該扣的分一分都沒放過。
結果讓我意外——其中有一題,Sonnet 4.6 直接把 Opus 4.6 打到 78 分,連 Opus 4.7 都小輸一分。到底是哪一題?等等揭曉。
這篇會依序帶你看三次實測的完整過程、每個模型的錯誤性格,以及我最後選模型的標準。
📌 重點整理
- 三次測試綜合分:Opus 4.7 = 89 分、Sonnet 4.6 = 84.3 分、Opus 4.6 = 84 分
- 視覺和編程 Opus 4.7 領先明顯,但繁中商業分析被 Sonnet 反超
- 三個模型各有錯誤性格:Sonnet 會幻覺、Opus 4.6 會疲勞、Opus 4.7 會誤讀結構
Claude Opus 4.7 vs Opus 4.6,官方數據透露了什麼訊號?
Anthropic 官方公布的 13 項 benchmark 裡,Opus 4.7 相較 Opus 4.6 幾乎每一項都領先,幅度從 0.4 個百分點到 13 個百分點都有。
但仔細翻那張表,有個細節很多評測文都跳過了:不同任務類型的落差很大,而且繁體中文使用者最在意的那一項,差距小到幾乎可以忽略。
先看官方數字(我挑出跟我測試最相關的六項):
測試項目 | Opus 4.6 | Opus 4.7 | 差距 |
|---|---|---|---|
視覺推理 CharXiv(無工具) | 69.1% | 82.1% | +13 |
編程 SWE-bench Pro | 53.4% | 64.3% | +10.9 |
編程 SWE-bench Verified | 80.8% | 87.6% | +6.8 |
終端編程 Terminal-Bench 2.0 | 65.4% | 69.4% | +4 |
研究生級推理 GPQA Diamond | 91.3% | 94.2% | +2.9 |
多語言問答 MMMLU | 91.1% | 91.5% | +0.4 |
有看到 MMMLU 那一欄嗎?這是「多語言問答」的測試,包含繁中、簡中、日文、韓文等多種非英語語言。Opus 4.7 只領先 Opus 4.6 少得可憐的 0.4 個百分點,這個差距幾乎可以視為測試誤差。
白話講,如果你主要的任務是繁中寫作、中文商業分析、台灣本地資訊查詢,Opus 4.7 帶給你的升級感,會遠低於你看官方數字時的期待。
視覺推理 +13 的高光時刻,發生在複雜圖表這種小眾場景;而我們每天用 Claude 寫文章、做研究、分析商業問題的情境,大部分落在 MMMLU 那個 +0.4 的區間。
這也是我設計三個實測任務的初衷。官方 benchmark 是基準,但不是使用體驗的全貌。三個測試跑完,我的懷疑被印證得很徹底。
📌 重點整理
- Opus 4.7 在視覺推理、編程任務領先明顯(+10 到 +13 個百分點)
- 多語言問答 MMMLU 只領先 0.4 個百分點
- 繁中使用者的實際升級感,會遠低於看官方數字的期待
測試 1:台積電財報圖片,三個模型誰抄數字最準?
這題標準答案存在 PDF 原檔裡,是三次測試中唯一能完全客觀評分的一題。結果:Opus 4.7 數字抄錄準確度 95 分最高,Opus 4.6 88 分中規中矩,Sonnet 4.6 只有 80 分,而且會幻覺,憑空生成不存在的數字。
測試設計
我拿了台積電 2026 Q1 的合併財務報表,包含資產負債表、綜合損益表、現金流量表,共 3 頁 PDF。裡面密集的數字、中英文混排、QoQ/YoY 百分比變化欄位,是實務上最難處理的圖片類型。
Prompt 是標準的圖片分析任務:提取文字、整理成 Markdown 表格、總結關鍵資訊、指出容易忽略的細節。
三個模型分別用 Extended Thinking(Sonnet 4.6、Opus 4.6)和 Adaptive Thinking(Opus 4.7)處理。
然後我做了一件很累的事:拿 PDF 原檔逐欄核對每一個數字。
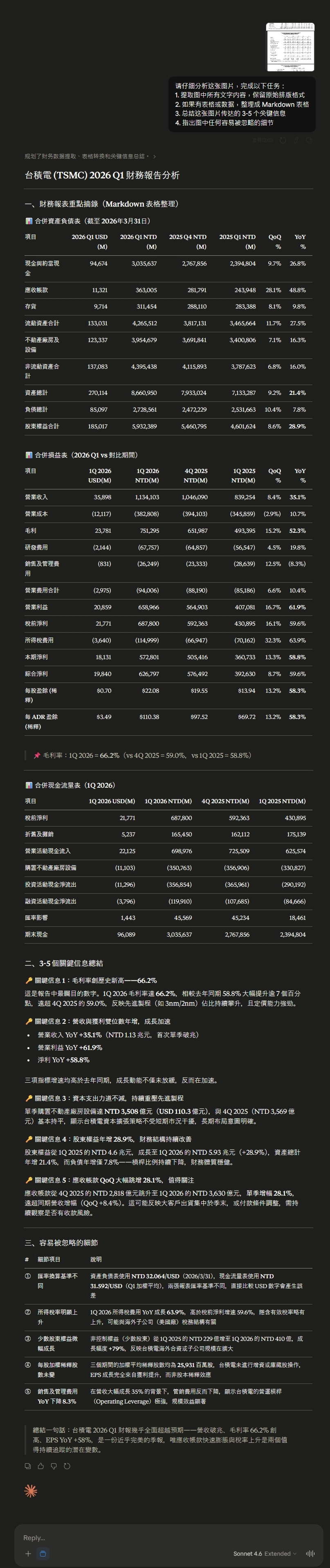
Sonnet 4.6:最大的雷是幻覺推論鏈
Sonnet 4.6 在這題的問題不只是抄錯數字,而是基於自己編造出來的數字,推導出一段看起來很有洞察力的分析:
「非控制權益(少數股東)從 1Q 2025 的 NTD 229 億增至 1Q 2026 的 NTD 410 億,成長幅度 +79%,反映台積電海外合資或子公司規模在擴大」
這段話的每個字讀起來都很合理,很像一個財務分析師會寫的話。問題是,PDF 上 1Q 2025 的非控制權益根本不是 229 億,是 374.62 億。正確的 YoY 成長率是 +10.6%,不是 +79%。
優點清單
- 表格呈現最乾淨:視覺化處理最好,有 emoji、粗體、引用框,整理起來最好閱讀
- 關鍵洞察方向正確:抓到毛利率 66.2%、營運槓桿效應等概念方向,雖然支撐數據有錯
缺點清單
- 數字準確度最低,且出現推論型幻覺(229 億、+79% 都是憑空編的)
- 結構精簡的代價是省略很多子項目:特別盈餘公積、資本公積等細節都被合併或直接跳過
- 推論建立在幻覺數字上:這是最危險的錯誤,不只是數字錯,連從錯誤數字推導出的洞察都是錯的
具體錯誤清單(對照 PDF 原檔)
欄位 | Sonnet 寫的 | PDF 正確值 | 錯誤類型 |
|---|---|---|---|
流動資產合計 2025/3/31 | 3,465,664 | 3,345,664 | 數字抄錯 |
4Q25 毛利率 | 59.0% | 62.3% | 關鍵數字抄錯 |
所得稅費用 4Q25 | (66,947) | (86,947) | 數字抄錯 |
非控制權益 1Q25 | NT$229 億 | NT$374.62 億 | 幻覺 |
非控制權益 YoY 增幅 | +79% | +10.6% | 幻覺 |
最後兩行那個紅色警報,是 Sonnet 4.6 最可怕的地方。典型的 AI 幻覺就長這樣:數字很具體、邏輯很流暢、結論很有洞察感,但整段內容是假的。
如果你是分析師,用 Sonnet 整理完財報直接貼進簡報,客戶一問細節的場面會非常難看。
這也是為什麼我做這份實測時,每個數字都回頭核對 PDF 一次——AI 寫的數字如果不驗證,很可能就是下一場會議上的地雷。
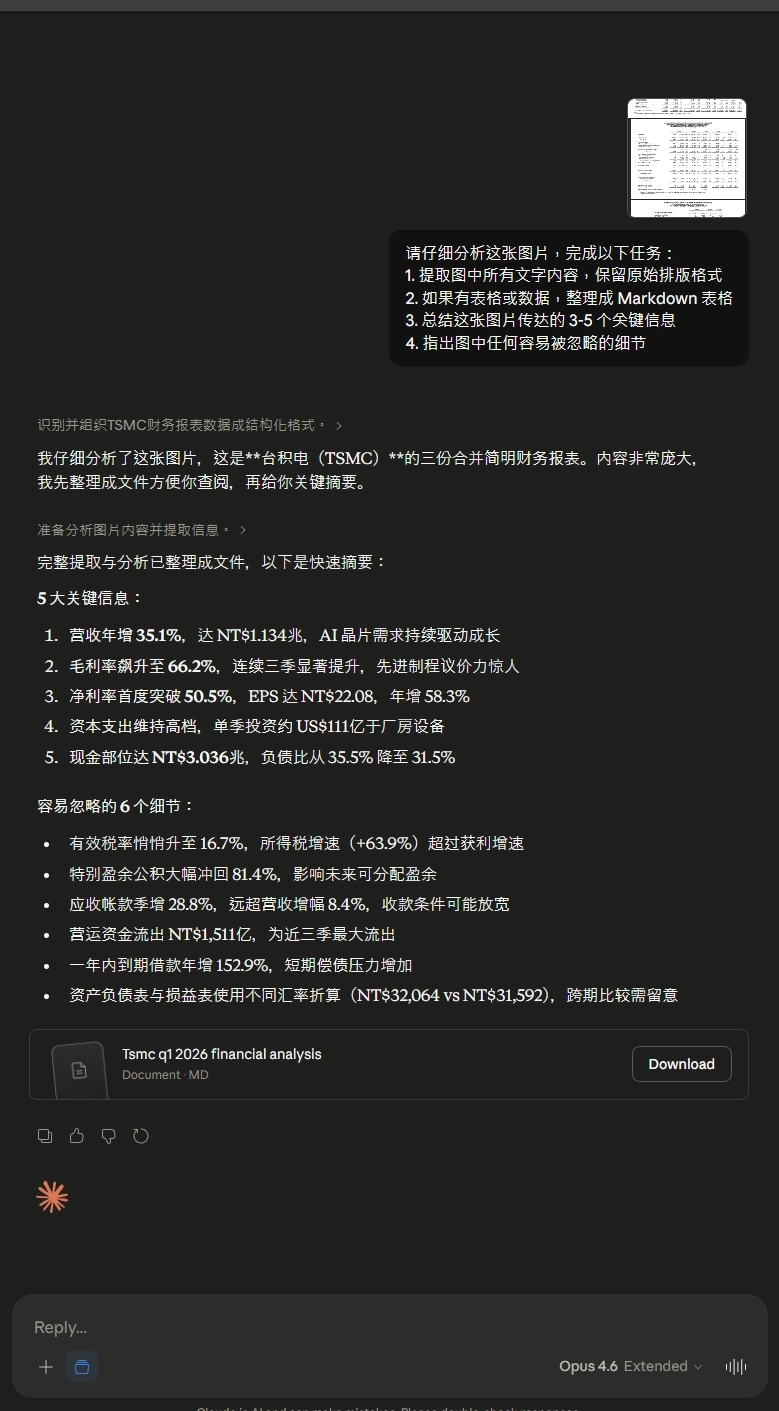

Opus 4.6:表格結構最完整,但末段會疲勞
Opus 4.6 在這題的表現像個會累的資深會計——前半段一絲不苟,到後半段開始打瞌睡。
優點清單
- 表格結構最完整:三張報表的每一個子項目都照原表提取,沒有合併、沒有省略,是三個模型裡架構最齊的
- 前半段準確度很高:資產負債表(第一張表)大部分數字都抄對,幾乎找不到錯誤
- 關鍵洞察品質好:特別盈餘公積 -81.4%、一年內到期借款 +152.9%、營運資金大幅流出等細節都有抓到
- 沒有推論型幻覺:所有錯誤都是「眼花看錯」,不是「憑空編造」
缺點清單
- 錯誤集中在現金流量表(最後一張表):7 處小錯裡有 6 處都集中在報表尾段,顯示模型在處理長文件時注意力衰減
- 期末匯率格式誤判:把 NT$32.064 讀成 NT$32,064,小數點被當成千分位(這種錯誤會被財務人員一眼看出)
- 整格漏掉:籌資活動 1Q25 那格直接空著沒填,表格看起來完整但實際有洞
- 數字抄錯有時候會差很多:長期投資 180,793 應為 160,793,6 和 8 的形狀相近導致誤讀
具體錯誤清單(對照 PDF 原檔)
欄位 | Opus 4.6 寫的 | PDF 正確值 | 錯誤類型 |
|---|---|---|---|
期末匯率格式 | NT$32,064 | NT$32.064 | 小數點誤判 |
長期投資 2025/3 | 180,793 | 160,793 | 數字抄錯 |
發放現金股利 4Q25 | (129,063) | (129,663) | 數字抄錯 |
籌資活動 1Q25 | 未填入 | (84,666) | 整格漏掉 |
Opus 4.6 的特性可以簡單歸納成一句話:需要完整原料、自己會再驗算的情境最適合它;但如果要把輸出直接當簡報素材,現金流量表的數字最好重新核對一次。

Opus 4.7:錯誤最少,但有一個特別的結構誤讀
Opus 4.7 的數字抄錄準確度是三個模型裡最高的,但它的錯誤類型最有意思——不是看錯數字,是看錯數字在表格中的角色。
原文的「特別盈餘公積」這一列,2025/3/31 欄位是「—」(空白,代表當時沒有這個科目)。QoQ 變化欄的 (71,085) 是「4Q25 的 87,284 減掉 2026/3/31 的 16,199」算出來的下降值。
Opus 4.7 把 QoQ 變化值誤讀為「1Q25 的原始數值」,然後延伸推論出「特別盈餘公積從 NT$87,284 百萬驟降至 NT$16,199 百萬」的結論。推論本身邏輯成立,但前提錯了——1Q25 當時根本沒有這個科目。
優點清單
- 數字抄錄準確度最高:四處錯誤中,三處只差一兩個數字(226,224 vs 226,024),沒有大幅偏差
- 主動做雙層輸出:artifact 放完整版 + 對話框放摘要版,實務上最好用
- 洞察品質跟 Opus 4.6 一樣好:都抓到關鍵的營運資金、稅率、借款結構等細節
- 易讀性最佳:表格排版最清楚,重點段落有明確標注
缺點清單
- 結構誤讀(獨家錯誤):把 QoQ 變化欄的數值當成 1Q25 原始值,推論方向從根上就錯了
- 對「空白欄位」處理不夠敏感:遇到「—」時沒有警覺這個科目當時可能不存在,直接當成數字的一種
- 基於誤讀的推論會誤導讀者:「-81.4% 驟降」的說法如果被分析師引用,會誤判公司財務狀況
具體錯誤清單(對照 PDF 原檔)
欄位 | Opus 4.7 寫的 | PDF 正確值 | 錯誤類型 |
|---|---|---|---|
使用權資產 2025/3/31 | 226,224 | 226,024 | 小錯 |
應付現金股利 2025/3/31 | 233,239 | 233,394 | 小錯 |
匯率變動 1Q25 | 18,461 | 16,461 | 小錯 |
特別盈餘公積 1Q25 解讀 | -711 億(負值) | 原表為空白 | 結構誤讀 |
這個錯誤最能說明 Opus 4.7 跟 Sonnet 的本質差異——Opus 4.7 的錯可以在 PDF 上追溯到來源(QoQ 變化欄確實有那個數字),Sonnet 的錯回頭找 PDF 是找不到的(229 億根本不存在)。
這個差別在後面的「錯誤性格」段會再展開。
三模型綜合評分
項目 | Sonnet 4.6 | Opus 4.6 | Opus 4.7 |
|---|---|---|---|
數字抄錄準確度 | 85 | 88 | 95 |
表格結構完整度 | 75 | 95 | 88 |
推論邏輯正確性 | 70 | 88 | 82 |
關鍵洞察品質 | 85 | 88 | 88 |
易讀性/實務可用性 | 85 | 82 | 92 |
綜合實用分 | 80 | 88 | 89 |
你可能注意到了,Opus 4.7 綜合只贏 Opus 4.6 一分(89 vs 88)。這呼應官方 benchmark 的「有工具模式 +6.3 個百分點」——Opus 4.6 在視覺任務上已經夠用,Opus 4.7 在這個場景下的升級感很邊際。
真正吃得到 Opus 4.7 視覺優勢的場景,是更極端的圖表推理,也就是 CharXiv 無工具模式 +13 個百分點那種難度。
另外 Opus 4.7 那個「特別盈餘公積」的錯誤,是把 QoQ 變化欄的數值誤讀為 1Q25 的原始值。數字是存在的,只是搞錯它在表格中的角色。
這跟 Sonnet 的幻覺本質完全不同:Opus 4.7 的錯可以在 PDF 上追溯到來源,Sonnet 的錯回頭找 PDF 是找不到的。這個差別很關鍵,後面的「錯誤性格」段落會再展開。
📌 重點整理
- Opus 4.7 = 89 分,Opus 4.6 = 88 分,Sonnet 4.6 = 80 分
- Sonnet 在這題出現嚴重幻覺,編造「229 億、+79%」的不存在數據
- 三個模型都不是 100% 準確,複雜財報圖片都要核對原檔
測試 2:React 番茄鐘編程,誰的代碼最能上線?
這題沒有標準答案,三個模型都產出可運行的代碼。但拆開看細節,差距就出現在「守不守技術規矩」和「有沒有前端真功夫」這兩件事上。
Sonnet 4.6 的 UI 最漂亮、但違反 Tailwind 要求;Opus 4.7 則是唯一處理了 AudioContext autoplay policy 的模型,這是真正前端老手才會留意的細節(關於用 AI 寫程式的更多實戰,可以看我另一篇 Vibe Coding 教學)。
測試設計
我給三個模型的 Prompt 是:用 React 寫一個完整的番茄鐘 Web App,單檔 .jsx。
要支援自訂時間、圓形進度條、提示音(Web Audio API 生成)、番茄數統計、開始/暫停/重置、完整邊界處理。技術要求我特別寫明樣式要用 Tailwind CSS。
評分方式從五個面向比較:是否可運行、是否遵守提示詞、代碼品質、UI 呈現、隱藏 bug。
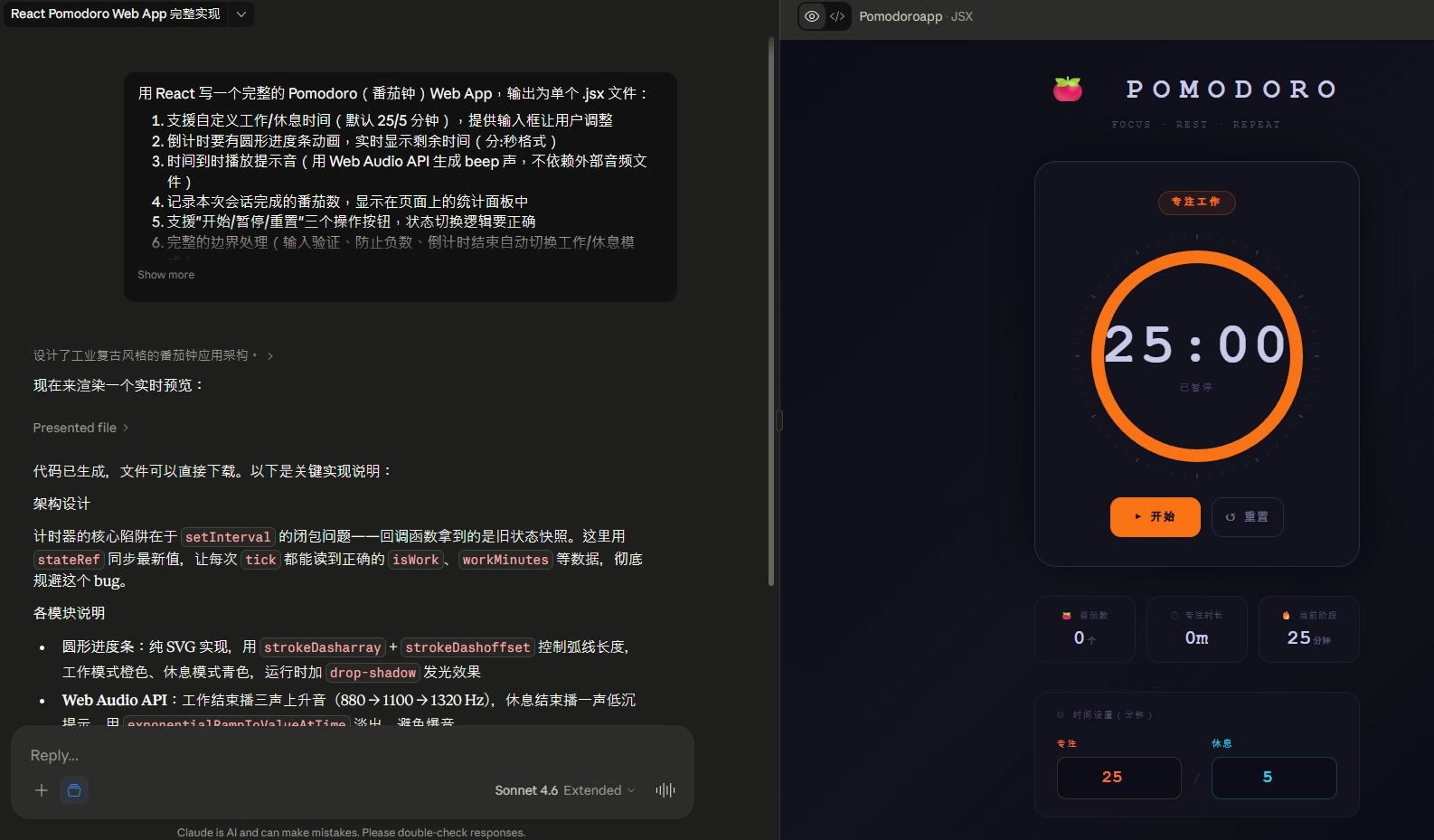
Sonnet 4.6:創造力爆表但不守規矩
Sonnet 4.6 的 UI 是三個模型裡最漂亮的。工業復古風、資訊密度最高、圓形進度條外圈有 60 個刻度點裝飾、三個統計卡片(番茄數、專注時長、當前階段)、頂部有 FOCUS/REST/REPEAT 導航條,視覺上最有儀式感。但功能做得多,問題也最多。
優點清單
- 狀態管理最穩健:用
stateRef解決 setInterval 的閉包陷阱——提示詞沒明確要求,Sonnet 自己想到了,這是資深前端才會注意到的細節 - Web Audio 最豐富:工作結束三聲上升音(880→1100→1320Hz)、休息結束一聲低沉音(440Hz),區分不同場景,其他兩個模型都只有一種音效
- 輸入防呆最嚴:用正則
/^\d{0,2}$/過濾非數字,不是只靠 HTML 驗證 - UX 貼心細節:切換階段後自動暫停,讓用戶主動開始下一階段,不會被突襲
- UI 資訊密度最高:三個統計卡片同時顯示,適合喜歡一眼看全貌的使用者
缺點清單
- 違反 Tailwind 技術要求(致命違規):提示詞明確寫「樣式用 Tailwind CSS 的核心工具類」,但 Sonnet 整份代碼 0 行 Tailwind,全部用 inline style
- 隱藏 bug:統計卡片「當前階段」欄位寫死
workMinutes,切到休息階段也不會變,label 和 value 會對不起來 - 硬編碼色碼:沒用任何設計 token,全是 hex 色碼,放進企業級專案會拆掉整個設計系統
- 整體傾向自作主張:跟測試 1 編造數字一樣,在編程任務裡它就是換掉你的技術棧
Tailwind 違規有多嚴重?看這個對照:
技術選擇 | Sonnet 4.6 | Opus 4.6 | Opus 4.7 |
|---|---|---|---|
樣式方案 | inline style(違規) | Tailwind | Tailwind |
顏色定義 | 硬編碼色碼 | Tailwind tokens | Tailwind tokens |
整合進既有專案 | 設計系統會斷裂 | 直接相容 | 直接相容 |
Sonnet 的自由派性格在這題不是優勢。它在測試 1 編造數字、在測試 2 換掉技術棧——這不是兩件事,是同一種性格的兩種表現。
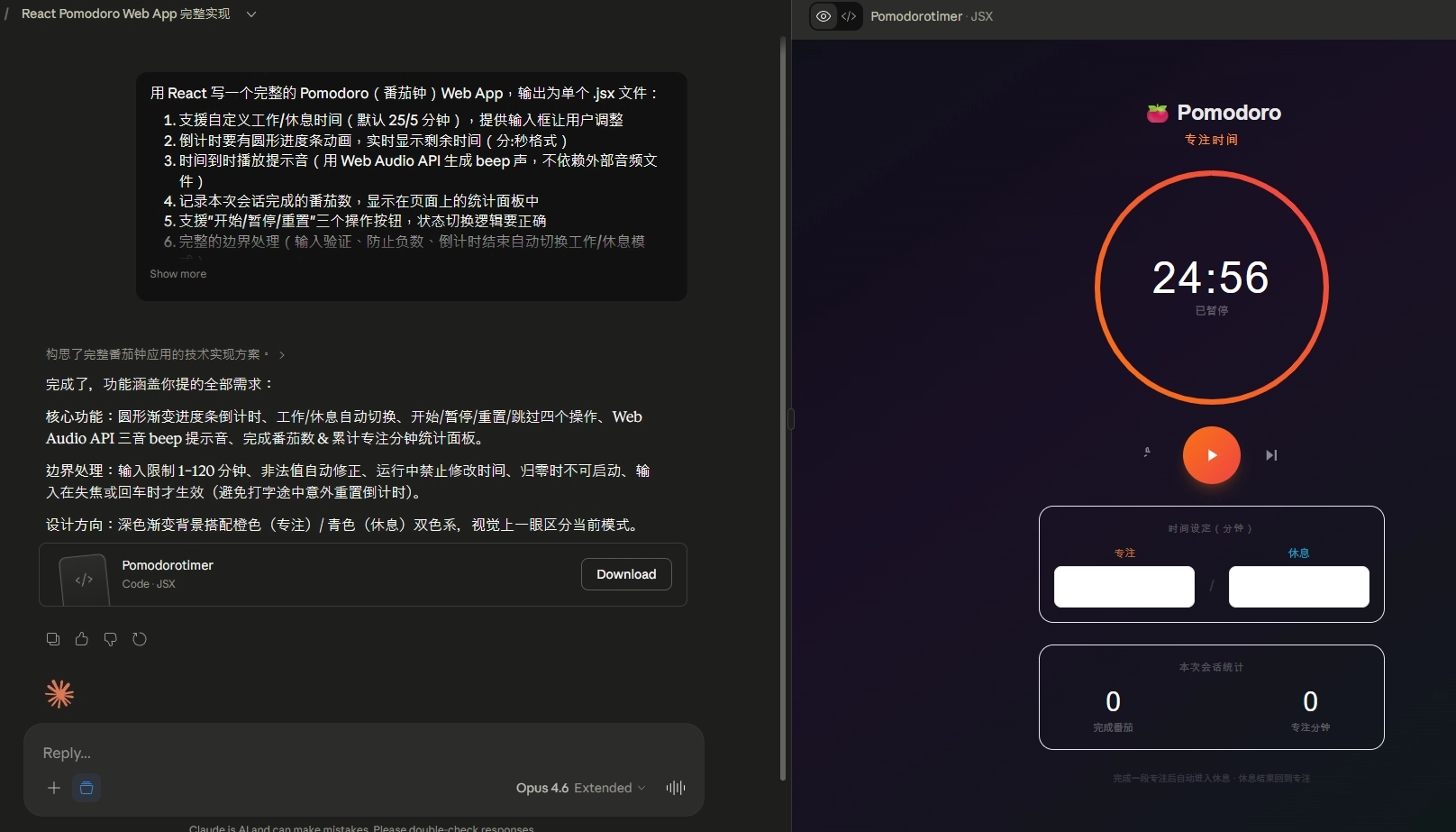
Opus 4.6:中規中矩可靠款
Opus 4.6 的 UI 是蘋果式極簡風。深色漸層背景、圓形大播放按鈕、工作階段用橘紅漸層、休息階段用青藍漸層,配色在三個模型裡最協調。而且它是中文 UI 最友善的——「完成番茄」「專注分鐘」這種標籤直接放在主介面,非工程師看也看得懂。
優點清單
- 最符合 Tailwind 精神:分離出獨立的
CircularProgress組件,使用 Tailwind 核心類,是三個模型裡唯一做元件分離的,代碼結構最接近真實專案 - SVG linearGradient 進度條:視覺效果最精緻,橘紅/青藍漸層切換時視覺舒服
- 中文 UI 最友善:「完成番茄」「專注分鐘」標籤直接放在主介面,非工程師看也看得懂
- 使用
tabular-nums:讓數字等寬,倒數時數字不會跳動(00:09→00:10 視覺不會抖動) - 遵守技術要求:Tailwind 用得正確,沒有 Sonnet 那種違規問題
缺點清單
- 自作主張加第四個「跳過」按鈕:提示詞只要求「開始/暫停/重置」三個,Opus 4.6 加了第四個。你可以說是貼心延伸,也可以說沒守住「按需求實作」的原則
- 沒有輸入防呆強化:只靠
type="number"+ min/max 屬性,如果貼上非整數要到 onBlur 才修正 - 狀態管理略冗餘:兩個 useEffect 分工,手動在 handler 裡呼叫
clearInterval,但 useEffect 本身會清理,有重複 - 時間到後會
setIsRunning(false):跟 Sonnet 一樣會暫停等用戶按開始,符合字面意思的「自動切換」但不符合「自動繼續」的隱含期待
Opus 4.6 這個「多加跳過按鈕」的舉動,跟 Sonnet 的 Tailwind 違規在性格上是同一種——都是主動幫你決定需求。
差別在於,Opus 4.6 的「加」比較無害(多一個按鈕不影響既有功能),Sonnet 的「換」會拆掉你的技術棧。嚴重度不同,但方向是一致的。
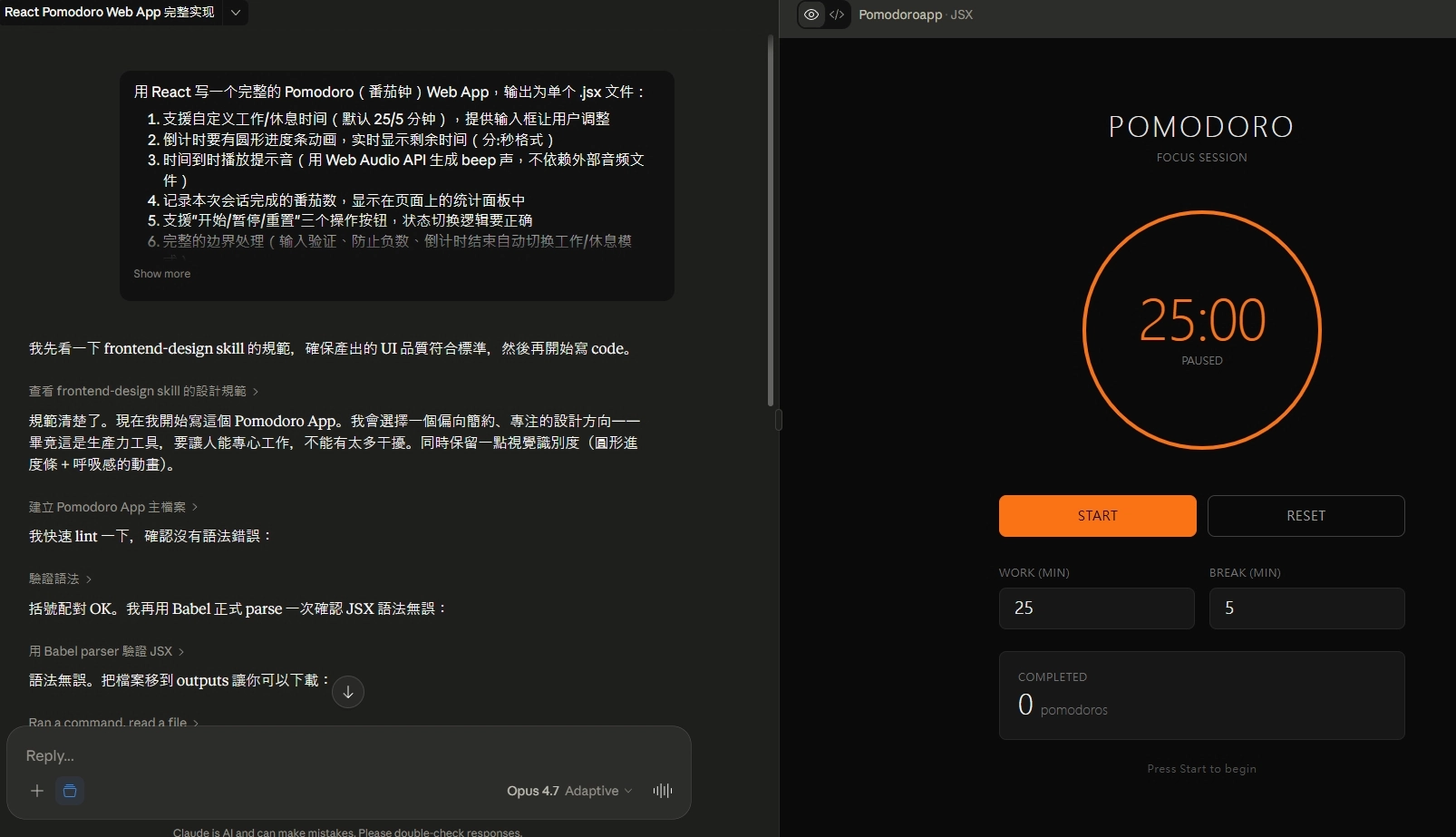
Opus 4.7:嚴謹守規矩且有前端真功夫
Opus 4.7 的 UI 是三個模型裡最樸素的——純粹幾何極簡、Neutral 色調、全英文 UI、數字版風格。工程師會喜歡,但對一般用戶偏冷冰冰。不過 UI 的樸素換來的是代碼品質最老練,特別是那些「真實部署才會遇到的細節」,只有它處理了。
優點清單
- 最守規矩:六大要求一一對應,沒多也沒少,沒有像 Sonnet 那樣違反技術棧,也沒有像 Opus 4.6 那樣自己加需求
- 代碼註釋品質最高:用繁體中文寫詳細註釋,解釋「為什麼這樣寫」——像「用 gain envelope 避免『啪』的爆音」這種備註,其他模型都沒寫
- AudioContext policy 處理(獨家):唯一處理了瀏覽器 autoplay policy,Safari 部署會少踩一大雷
- Web Audio envelope 最精緻:用
linearRampToValueAtTime做 fade in/out,避免開始結尾的爆音 - 模組劃分最清楚:
MODE常數避免字串 typo、switchMode獨立 callback、setter/getter 分得清楚 - 視覺化番茄點:完成的番茄用小圓點顯示(最多 8 個,超過顯示 +N),比單純顯示數字更有成就感
AudioContext policy 這段代碼長這樣:
const handleStartPause = () => {
if (!audioCtxRef.current) {
const AudioCtx = window.AudioContext || window.webkitAudioContext;
if (AudioCtx) audioCtxRef.current = new AudioCtx();
}
if (audioCtxRef.current?.state === "suspended") {
audioCtxRef.current.resume();
}
setIsRunning((prev) => !prev);
};
現代瀏覽器(特別是 Safari 和 Chrome)為了防止廣告網站自動播放音效干擾用戶,規定 AudioContext 必須在「用戶明確互動」後才能播放聲音。
如果沒有在用戶點擊時呼叫 resume(),AudioContext 會卡在 suspended 狀態,音效就是不會響。
💡 為什麼這個細節很重要? 其他兩個模型的音效,在 Safari 第一次點「開始」時很可能不會響,用戶要點第二次才響。不是 bug,是瀏覽器安全機制。
Opus 4.7 主動處理了這塊,代表它對「真實世界前端部署會遇到什麼問題」有更深的理解。不只是寫「能跑的代碼」,而是寫「部署後不會被 QA 打回來的代碼」。
缺點清單
- UI 最「無趣」:全英文、純幾何、沒裝飾。工程師會喜歡,一般用戶覺得冷冰冰
- 統計資訊最少:只有完成番茄數,沒有 Opus 4.6 的「專注分鐘」這種累積統計,使用者儀式感較弱
- setTimeout race workaround:在 setInterval 裡用
setTimeout(() => switchMode(), 0)跳出 setter,理論上極端時序下可能有問題(實務上不太會) - 預設值寫死 magic number:
handleBlur(setMinutes, 25)裡的 25 沒用常數,改維護時要手動找
前端真功夫就是這麼回事,不是靠大量記憶 API,而是靠對實際部署場景的理解。Opus 4.7 的 UI 雖然最樸素,但它寫的是會通過 code review 的代碼,其他兩個模型的代碼要上線前還得再改一輪。
三模型綜合評分
項目 | Sonnet 4.6 | Opus 4.6 | Opus 4.7 |
|---|---|---|---|
遵守提示詞 | 70 | 85 | 95 |
代碼結構可讀性 | 85 | 88 | 95 |
功能完整度 | 90 | 88 | 85 |
UI 設計品質 | 95 | 90 | 80 |
狀態管理穩健性 | 92 | 85 | 88 |
邊界處理嚴謹度 | 88 | 82 | 90 |
Web Audio 細節 | 88 | 82 | 92 |
隱藏 bug 數量 | 2 處 | 1 處 | 0 處 |
綜合實用分 | 84 | 86 | 90 |
Opus 4.7 以 90 分領先。官方 SWE-bench Pro +10.9 個百分點的差距,在這個測試化為 +4 分。原因是番茄鐘只是中等難度任務,不是 SWE-bench Pro 那種極難的真實專案修復題。但模型性格的差異,在編程任務上更明顯:
- Sonnet 4.6:UI 最漂亮但自由派,會換掉你的技術棧
- Opus 4.6:中規中矩,什麼都不差但也不驚艷
- Opus 4.7:嚴謹守規,代碼品質最高、細節處理最老練
你要做 prototype 給老闆看一眼就丟,Sonnet 4.6 的 UI 最能打。你要把代碼直接交付、進生產環境,Opus 4.7 會讓你少踩很多雷。選哪個,看你的場景。
📌 重點整理
- Opus 4.7 = 90 分,Opus 4.6 = 86 分,Sonnet 4.6 = 84 分
- Sonnet 4.6 違反 Tailwind 技術要求,全用 inline style
- Opus 4.7 是唯一處理 AudioContext autoplay policy 的模型,Safari 部署會少踩雷
測試 3:台灣商業分析,為什麼Sonnet 反而贏了?
重頭戲來了。這是三次測試裡唯一的反轉:Sonnet 4.6 拿到 89 分,Opus 4.7 只有 88 分,Opus 4.6 甚至掉到 78 分。
不是我故意寫得驚悚,是三重交叉驗證後的結果。反轉的關鍵,跟前面提到的 MMMLU 那 0.4 個百分點有直接關聯。
測試設計
我用一個貼近台灣創業者的問題測三個模型:「我想在台灣做線上課程平台,從法律註冊、稅務申報、消費者保護三個面向,給我完整建議」。
這題難在哪?難在需要最新的台灣本地資訊。財政部 2024/12/12 公告、2025/1/1 起生效的新稅制、消保法第 19 條的網購鑑賞期規定、2025/10 PressPlay 整併 YOTTA 這類產業動態,都是關鍵。
我用三重交叉驗證準備標準答案:政府資料(財政部、消保法)、會計師意見(元方聯合)、商務中心實務(史貝斯),三方說法一致才算數。
三個模型在三大關鍵查證的說法對照
先把三個最有爭議的查證攤開來看,一眼就能看出差距在哪。
查證 1:台灣小規模營業人稅率(2025 年新制)
正確答案:勞務業起徵點月 NT$50,000、小規模營業人稅率 1%(不是一般營業人的 5%)、開發票門檻月 NT$200,000(年 240 萬)。
模型 | 說法 | 正確性 |
|---|---|---|
Sonnet 4.6 | 月均銷售超過 NT$20,000 建議諮詢會計師評估 | 數字非法定門檻,但用「建議諮詢」包裝,不算錯 |
Opus 4.7 | 年超 NT$480,000 則屬應開發票對象 | 數字錯 5 倍(實際年 240 萬) |
Opus 4.6 | 月營收超過 NT$40,000 須繳營業稅 5% | 雙重錯(起徵點用舊版 + 稅率完全錯) |
查證 2:消保法線上課程鑑賞期
正確答案:線上課程屬「一經提供即為完成的數位內容」,可排除 7 日鑑賞期,但必須事先在購課頁面顯著告知。
模型 | 說法 | 正確性 |
|---|---|---|
Sonnet 4.6 | 引用消保法第 19 條 + 購課頁面必須顯著告知 | 法條引用精準 |
Opus 4.7 | 完全沒提 | 遺漏 |
Opus 4.6 | 完全沒提 | 遺漏 |
查證 3:PressPlay 2025/10 整併 YOTTA 時效性
模型 | 說法 | 時效性 |
|---|---|---|
Sonnet 4.6 | 2025 年整併 YOTTA 後規模擴大 | 準確抓到近期事件 |
Opus 4.7 | 有提 PressPlay 但沒提整併 | 聲稱搜尋但沒抓到重點 |
Opus 4.6 | 完全沒提 PressPlay | 跳過台灣御三家之一 |
三個查證跑完,三個模型的輪廓就清楚了。接下來逐一拆解各自的完整表現。

Sonnet 4.6:這次的意外贏家
Sonnet 4.6 在這題交出了前兩次測試看不到的穩健表現。
優點清單
- 消保法第 19 條引用最精準:三個模型裡唯一寫出「數位商品可例外排除 7 日鑑賞期,但購課頁面必須顯著告知」的完整配套
- PressPlay 2025/10 整併 YOTTA 直接寫進競品分析:近期產業動態的覆蓋度最好
- 食安法廣告規定提醒:「課程若涉及食品教學,廣告文案中禁止出現任何醫療或功效宣稱」,這條抓得很細
- MoSCoW 判斷最穩:講師直播正確分到 Won't(一人預算 5 萬做不起直播的設備、排程、平台)
- 稅務用「建議諮詢會計師」包裝:雖然數字不精確,但避開了明確錯誤
缺點清單
- 稅務數字不精確:「月均 NT$20,000」不是法定門檻,實際勞務起徵點是月 NT$50,000,Sonnet 用「建議諮詢」打了模糊仗
- 預算算得最省(NT$15,280):沒把拍攝器材、素材外包這些隱藏成本算進來,新手照抄會低估實際支出
- 沒提公司 vs 行號的架構選擇:這是創業第一個該決定的事,Sonnet 漏了
- 沒顯示搜尋過程:但內容卻最準確,可能是訓練資料本身就有這些資訊,運氣成分佔一部分
Sonnet 的性格在這題反而變成優勢。前兩個測試它會編造數字、違反規格,但在「沒有標準答案、需要綜合多個本地知識來源」的題目上,這種自由度讓它更敢引用具體條款、更敢提具體事件。這次的贏,贏在「不敢亂講」,剛好遇到任務需要「保守整合」而不是「精確比對」。

Opus 4.6:商業分析的明確敗筆
Opus 4.6 這次踩的雷不是一個兩個,是好幾個,其中一個會害讀者多繳 4 倍稅。但它也不是全盤皆輸,有幾個實務細節反而比 Sonnet 還要完整。
優點清單
- 食譜著作權細節最精準:「甜點食譜本身不受著作權保護,但教學影片中若使用他人配方的文字描述、步驟照片、品牌名稱則可能觸法」——這段話三個模型裡它講得最完整
- 背景音樂版權提醒 + 具體資源:直接給出「YouTube Audio Library」這個無版權音樂來源,三個模型中唯一寫出具體替代方案的
- 風險分析結構完整:稅務 + 著作權兩個層面都有覆蓋,沒有漏層
- Teachable vs Teachify 選型邏輯清楚:兩個平台的差異、適用情境都有說明
缺點清單(這次最嚴重)
- 稅務雙重錯誤:
- 起徵點用 2024 年舊版:「月營收超過 NT$40,000 須辦理營業登記」,2025/1/1 起已調整為 NT$50,000
- 稅率完全錯:「繳納營業稅 5%」,小規模營業人實際是 1%,5% 是每月 20 萬以上的一般營業人才適用
- MoSCoW 把「講師直播」分到 Could:一人預算 5 萬吃不下直播的設備、排程、平台,應該放 Won't
- 完全沒提 PressPlay:跳過台灣線上課程御三家之一
- 「學籽 Seeds」競品存在疑問:這個平台名稱不是市場主流,可能是記錯或不精確
- Teachify 年費 NT$12,000 整個算進首月:年費應按月攤提 NT$1,000/月,計算邏輯錯了
- 沒提公司 vs 行號的架構選擇:三個模型都漏,但 Opus 4.6 漏得最完整
⚠️ 稅率錯誤到底多嚴重? 台灣小規模營業人(月營收 20 萬以下)的營業稅率是 1%,不是一般營業人的 5%。
如果有人看了 Opus 4.6 的建議,以 5% 去申報月營收 40,000 元的課程收入,他會多繳 1,600 元——正確應繳 400 元,被 Opus 4.6 算成 2,000 元,多繳 4 倍。不是小錯,是會害到讀者的錯。
Opus 4.6 的錯誤本質,跟 Sonnet 的幻覺完全不同。它沒有憑空編造數字,抄的起徵點、稅率、競品名稱,都是訓練資料裡存在的資訊,只是訓練資料停留在 2024 年的舊規,而且對「小規模營業人」和「一般營業人」的稅率差異沒分清楚。
這是「知識邊界 + 架構理解」的問題,不是幻覺。但對使用者來說結果是一樣的——看不出來就會照做,照做就出事。

Opus 4.7:聲稱搜尋,卻沒搜到重點
Opus 4.7 這次的表現最讓我困惑。商業洞察是三個模型裡最深的,但在時效性上被 Sonnet 超車。
優點清單
- 商業洞察最深:「副業客群自帶分享動機」推論出 LINE 分潤的價值;「副業客群需儀式感與完課率」推論出學習進度追蹤的重要性——這種推論鏈 Sonnet 和 Opus 4.6 都沒有
- 預算計算最完整:主動加上「拍攝器材補齊 NT$8,000、廣告素材外包 NT$5,000」這些隱藏成本,三個模型中唯一想到的
- 具體細節最多:直接點名 Tim 主廚法式甜點課、金老師鏡面蛋糕課、小鳳、佐山真衣等真實課程/講師
- 小規模營業人基本描述正確:「每月銷售額 20 萬以下、營業稅率 1%」這點對,跟 Opus 4.6 的 5% 形成鮮明對比
- 產品責任險建議:三個模型中唯一提到保險機制
缺點清單
- 發票門檻數字錯 5 倍:「年超 NT$480,000 則屬應開發票對象」——實際是月 NT$200,000(年 240 萬)
- MoSCoW 把學習進度追蹤放 Must:有洞察但略過頭,嚴格說應該是 Should(Must 是不做就不能上線)
- 聲稱搜尋但時效性不佳:開頭寫「我先搜一下……確保競品資訊準確」,但沒抓到 2025/10 PressPlay 整併 YOTTA 這個重大事件
- 沒提消保法鑑賞期:這是線上課程最重要的法律風險之一,Opus 4.7 完全沒觸及
- 沒提公司 vs 行號選擇:同樣漏了這個決策點
這次最大的警訊是「聲稱搜尋 ≠ 實際抓到最新資訊」。一般使用者普遍以為「有搜尋的模型 = 時效性最強」,但這次 Sonnet 沒顯示搜尋過程卻講對了,Opus 4.7 顯示搜尋過程卻沒講到重點。
Adaptive Thinking 的搜尋可能只搜基礎資訊,錯過近期重大變化——這跟多數人的直覺剛好相反。
公司 vs 行號:三個模型都漏掉的重點
有意思的是,即使是贏家 Sonnet 4.6,也有重要的盲區。三個模型沒有一個提到「公司 vs 行號」的架構選擇。
這對台灣小型創業者是關鍵決策:
項目 | 公司(有限/股份) | 行號(獨資/合夥) |
|---|---|---|
註冊資本 | 最低 1 元(實務 5-10 萬) | 無限制 |
負責人責任 | 有限責任(以出資額為限) | 無限責任(要賠全部身家) |
稅務 | 營所稅 20% + 股利稅 | 綜所稅 5-40% 級距 |
適合規模 | 預期年營收 > 300 萬 | 年營收 < 100 萬 |
帳務複雜度 | 需要會計師簽證 | 相對簡單 |
三個模型都預設「一定要開公司」,但對月營收幾萬塊的個人老師來說,開行號反而比較划算。這是 AI 工具在本地知識上的共同盲區,不管你用哪個模型,重大決策還是得找真人會計師。
三模型綜合評分
項目 | Sonnet 4.6 | Opus 4.6 | Opus 4.7 |
|---|---|---|---|
法規引用精準度 | 92 | 75 | 88 |
稅務資訊正確性 | 90 | 65(5% 錯誤) | 88 |
時效性(最新事件) | 90 | 78 | 85 |
實務可執行度 | 88 | 85 | 90 |
結構清晰度 | 85 | 85 | 90 |
綜合實用分 | 89 | 78 | 88 |
為什麼會反轉?
我覺得有兩個原因疊加。
第一,MMMLU 那 0.4 個百分點的差距在這題顯現了。繁中商業分析對 Opus 4.7 來說不是強項,它的訓練強化重點在編程和視覺推理,也就是官方 benchmark 看到的 +10 到 +13 的差距。多語言問答幾乎沒進步,真的拿到實戰就是打回原形。
第二,Sonnet 4.6 的「自由派」性格在這題反而是優勢。前兩個測試它會編造數字、違反規格,但在「沒有標準答案、需要整合多個本地知識來源」的商業分析題上,這種自由度反而讓它更敢引用具體條款(第 19 條),更敢提具體事件(PressPlay 整併)。
當然不是說 Sonnet 4.6 真的比 Opus 4.7 強,在財報和編程任務上,Sonnet 落後非常明顯。但在繁中本地商業情境,Sonnet 的性格優勢蓋過了模型規模劣勢。看任務,不看價格。
📌 重點整理
- Sonnet 4.6 = 89 分反超,Opus 4.7 = 88 分,Opus 4.6 = 78 分(嚴重掉分)
- Opus 4.6 把小規模營業人稅率 1% 寫成 5%,會害讀者多繳 4 倍稅
- 三個模型都漏掉「公司 vs 行號」架構,本地知識仍需真人專家把關
三個模型的「錯誤性格」完全不同,怎麼避開地雷?
看完三次實測,我發現一件比分數更重要的事:三個模型犯錯的方式完全不一樣。知道每個模型的錯誤性格,比知道它們幾分更有用,因為你可以針對性地避開每個模型的地雷。
三種錯誤本質
Sonnet 4.6 是「幻覺型」錯誤。憑空生成不存在的數字或事實,然後用這些假數據推導出看起來合理的結論。在財報測試裡編造「229 億、+79%」就是典型案例。這種錯誤最危險,因為回頭看原始資料完全找不到對應,只能靠用戶自己起疑心去核對。
Opus 4.6 是「疲勞型」錯誤。前半段處理得很好,越到文件末尾錯誤越多。在財報測試裡,資產負債表(第一張)幾乎全對,但到了現金流量表(最後一張),一連串小錯跑出來:整格漏掉、數字抄錯。
這種錯誤相對好抓,知道它會末段疲勞,重點核對文件後半段就能攔下大部分錯誤。
Opus 4.7 是「誤讀型」錯誤。數字抄得最準,但偶爾會把表格欄位的角色搞錯。把 QoQ 變化值誤讀為原始數值、把空白欄位解讀成 -71,085,都是這種類型。這種錯誤在邏輯上成立但前提錯了,數字可以在原檔追溯,但「這個數字代表什麼意思」需要二次驗證。
三種錯誤的風險等級對照:
項目 | Sonnet 4.6 幻覺 | Opus 4.6 疲勞 | Opus 4.7 誤讀 |
|---|---|---|---|
錯誤可驗證性 | 低(找不到對應) | 中(對得上但抄錯) | 高(數字存在) |
驗證成本 | 高(要從頭核對) | 中(只需核末段) | 中(要確認欄位關係) |
對決策的風險 | 🔴 極高 | 🟡 中 | 🟡 中 |
使用者信任陷阱 | 邏輯流暢難察覺 | 數字看起來合理 | 推論方向可能錯 |
哪個任務該選哪個模型?
任務情境 | 推薦模型 | 理由 |
|---|---|---|
財報圖片提取、需要直接當簡報素材 | Opus 4.7 | 數字準確度最高,雖然偶爾誤讀欄位 |
需要完整細節、自己會驗算 | Opus 4.6 | 表格結構最完整,末段記得核對 |
快速瀏覽、不用於決策 | Sonnet 4.6 | 但要有「可能幻覺」的警覺 |
React / Next.js 企業級開發 | Opus 4.7 | 代碼品質最高、AudioContext 這類細節到位 |
前端 prototype 視覺衝擊力 | Sonnet 4.6 | UI 最豐富,但要檢查是否換掉你的技術棧 |
符合團隊規範的一般編程 | Opus 4.6 | 遵守 Tailwind、中規中矩 |
繁中商業分析、台灣本地資訊 | Sonnet 4.6 | 唯一反超案例,但重大決策仍需真人專家 |
極度複雜的圖表推理(學術級) | Opus 4.7 | 官方 benchmark 差距最大的場景 |
三個性格,一個結論
一句話總結三個模型的性格:
1️⃣ Sonnet 4.6 是那種「點子多但不太守規矩」的實習生。給他自由度高的任務會有驚喜,但重要文件要盯緊,他可能會自作主張。
2️⃣ Opus 4.6 是那種「可靠但會累」的中階員工。長期專案交給他放心,但連續處理長文件要記得給他喘息,末段品質會掉。
3️⃣ Opus 4.7 是那種「嚴謹但偶爾鑽牛角尖」的資深工程師。複雜任務給他最放心,但面對不在他擅長領域的繁中本地題,不見得比 Sonnet 強多少。
選模型跟選員工一樣,不是找最強的那個,是找最符合當前任務性格的那個。
如果想看更多 AI 模型在不同情境下的實測對比,可以接著看這篇 Claude Opus 4.5、GPT-5.1、Gemini 3 Pro 三模型實測比較。
📌 重點整理
- 三種錯誤性格:幻覺型(Sonnet)、疲勞型(Opus 4.6)、誤讀型(Opus 4.7)
- 驗證成本:Sonnet 最高、Opus 4.6 中、Opus 4.7 中
- 選模型不是選最強,是選最符合任務性格的那個
常見問題
Claude Opus 4.7 值得從 Opus 4.6 升級嗎?
看你的主要任務類型。如果你每天做視覺推理、複雜編程、科學研究,升級有感(官方 benchmark +6 到 +13 個百分點,實測 +1 到 +4 分)。
如果主力任務是繁中寫作、台灣本地商業分析,差距只有 0.4 個百分點(MMMLU),升級的邊際效益很低。
我自己的做法是:視覺和編程任務交給 Opus 4.7,繁中內容寫作留在 Opus 4.6 或 Sonnet 4.6。如果你還在 ChatGPT 跟 Claude 之間猶豫,可以參考我寫的三大付費 AI 到底怎麼選。
Sonnet 4.6 真的夠用嗎?什麼情境會不夠?
大部分日常情境是夠用的,特別是繁中內容寫作、一般問答、創意發想。但有三個情境要特別小心:涉及具體數字的引用(會幻覺)、複雜財務分析(準確度最低)、有明確技術規格的編程任務(會自作主張違反規格)。要用 Sonnet 整理數據做簡報,強烈建議核對原始資料。
台灣用戶做繁中商業分析該選哪個 Claude 模型?
根據我的測試 3,Sonnet 4.6 實際表現最好(89 分),Opus 4.7 次之(88 分),Opus 4.6 反而最差(78 分)。
但要提醒,三個模型都有「本地知識盲區」,例如沒一個提到「公司 vs 行號」的架構選擇,稅務細節也可能過時。AI 可以當起手式的研究助手,但重大商業決策還是要找真人會計師或律師。
Opus 4.7 的 Adaptive Thinking 搜尋可以完全信任嗎?
不行。在我的測試 3 裡,Opus 4.7 開頭宣稱「我先搜一下最新資訊,確保準確性」,搜尋工具也啟動了,但它沒抓到 2025 年 10 月 PressPlay 整併 YOTTA 這個產業大事。
Adaptive Thinking 的搜尋會提高時效性,但不代表一定抓到所有重要資訊。對時效敏感的題目,仍然建議自己用 Google 再驗證一次。
這次實測結果跟 Anthropic 官方 benchmark 有什麼差異?為什麼?
差異在「差距的絕對大小」。官方 benchmark 顯示 Opus 4.7 在編程任務領先 Opus 4.6 +10.9 個百分點,我實測番茄鐘編程只領先 +4 分;官方視覺推理領先 +13,我實測財報圖片只領先 +1。
原因是官方測試難度集中在高難度邊緣案例,而日常任務大多落在兩個模型都能處理好的中等難度區,差距會被壓縮。官方數字是天花板,實測體驗接近地板,取中間值當期待比較務實。
結論:沒有一個模型是 打遍天下無敵手的
花一個晚上做完這三個實測,我最大的收穫不是「知道哪個模型最強」,而是知道每個模型有適合的任務範圍,以及它們各自的弱點在哪。
三次測試的平均分是 Opus 4.7 = 89、Sonnet 4.6 = 84.3、Opus 4.6 = 84。Opus 4.7 平均最高,但三次裡有一次被 Sonnet 反超,Opus 4.6 在台灣商業分析上嚴重掉分。
這些細節,只有實測才看得出來——光看官方 benchmark,你會以為 Opus 4.7 挑不出毛病(類似的多模型實測,我之前還做過 AI 寫小說的對決,有興趣可以對照看)。
如果你問我該怎麼選:
1️⃣ 預算充足、主要做視覺和編程任務 → Opus 4.7
2️⃣ 主要做繁中內容寫作、不常碰複雜財務和編程 → Sonnet 4.6 就夠
3️⃣ 已經在用 Opus 4.6,不確定要不要升級 → 看你做什麼,純繁中任務可以先留著
最後一句話送給每個在用 AI 工具的人:AI 是起手式的加速器,不是終點線的裁判。這三個模型加起來每個月的訂閱費可以請一個兼職顧問,但沒有哪一個能取代真人專家的最終把關。知道它們的錯誤性格,才能真正用好它們。
延伸閱讀
- Claude Opus 4.7 是什麼?5 大升級重點一次看懂【2026 最新】
- Claude Opus 4.5、GPT-5.1、Gemini 3 Pro 比較:實測後告訴你怎麼選
- Claude、ChatGPT、Gemini 三大付費 AI 到底怎麼選?2026 最新購買建議
- Claude 寫 SEO 文章怎麼做?從選題到發佈的完整內容工作流教學



